我搜索了Python中实现降维的方法,得到了以下结果:http://scikit-learn.org/stable/modules/unsupervised_reduction.html。该网站中展示的最后一种方法是特征聚合。我点击了该Python方法的文档链接,但仍然不确定如何使用它。
如果有人之前使用过Python的特征聚合方法,能否解释一下它的工作原理(输入、输出等)?谢谢!
如果有人之前使用过Python的特征聚合方法,能否解释一下它的工作原理(输入、输出等)?谢谢!
from sklearn.cluster import FeatureAgglomeration
import pandas as pd
import matplotlib.pyplot as plt
#iris.data from https://archive.ics.uci.edu/ml/machine-learning-databases/iris/
iris=pd.read_csv('iris.data',sep=',',header=None)
#store labels
label=iris[4]
iris=iris.drop([4],1)
#set n_clusters to 2, the output will be two columns of agglomerated features ( iris has 4 features)
agglo=FeatureAgglomeration(n_clusters=2).fit_transform(iris)
#plotting
color=[]
for i in label:
if i=='Iris-setosa':
color.append('g')
if i=='Iris-versicolor':
color.append('b')
if i=='Iris-virginica':
color.append('r')
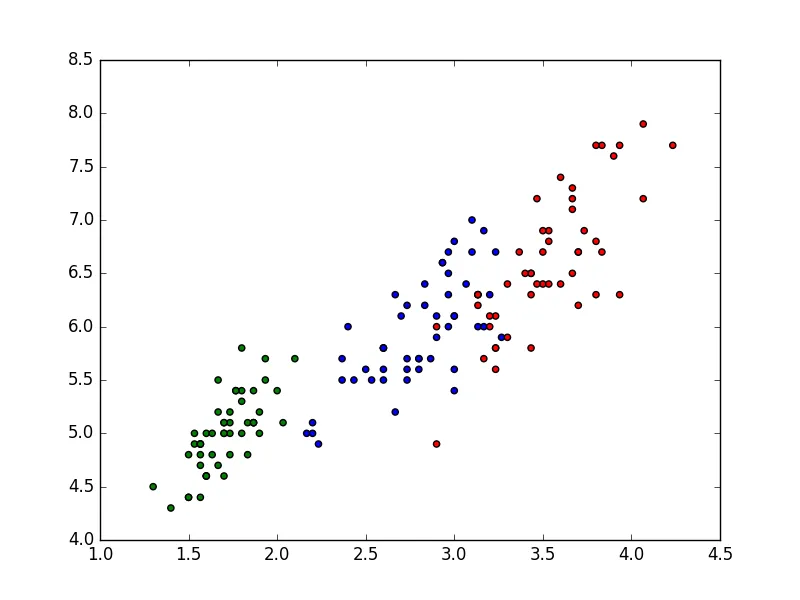
plt.scatter(agglo[:,0],agglo[:,1],c=color)
plt.show()