我想把一个字典存储到数据框中。
那让它们进入了...
dictionary_example={1234:{'choice':0,'choice_set':{0:{'A':100,'B':200,'C':300},1:{'A':200,'B':300,'C':300},2:{'A':500,'B':300,'C':300}}},
234:{'choice':1,'choice_set':0:{'A':100,'B':400},1:{'A':100,'B':300,'C':1000}},
1876:{'choice':2,'choice_set':0:{'A': 100,'B':400,'C':300},1:{'A':100,'B':300,'C':1000},2:{'A':600,'B':200,'C':100}}
}
那让它们进入了...
id choice 0_A 0_B 0_C 1_A 1_B 1_C 2_A 2_B 2_C
1234 0 100 200 300 200 300 300 500 300 300
234 1 100 400 - 100 300 1000 - - -
1876 2 100 400 300 100 300 1000 600 200 100
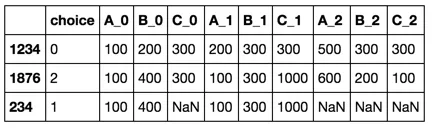
merge步骤,因为没有它,我们会丢失“choice”列。我注意到在此过程中,多级索引被压缩成其元组等效形式。 - Svendmerge前,您需要执行flattened_choice_set.columns = ['_'.join((str(col[0]), col[1])) for col in flattened_choice_set.columns]。 - jezrael