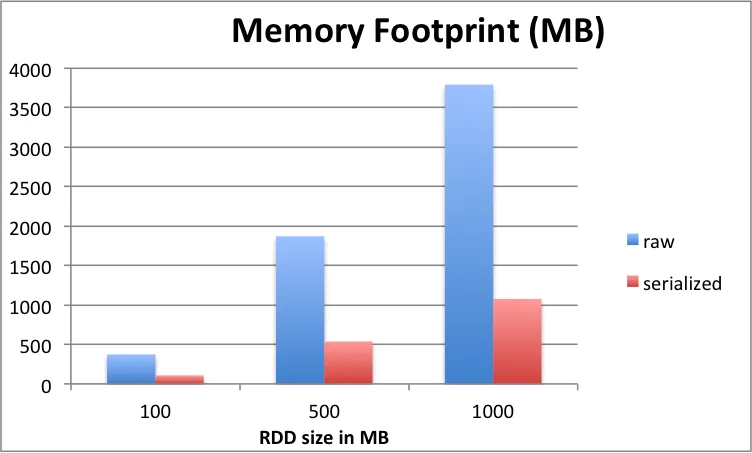
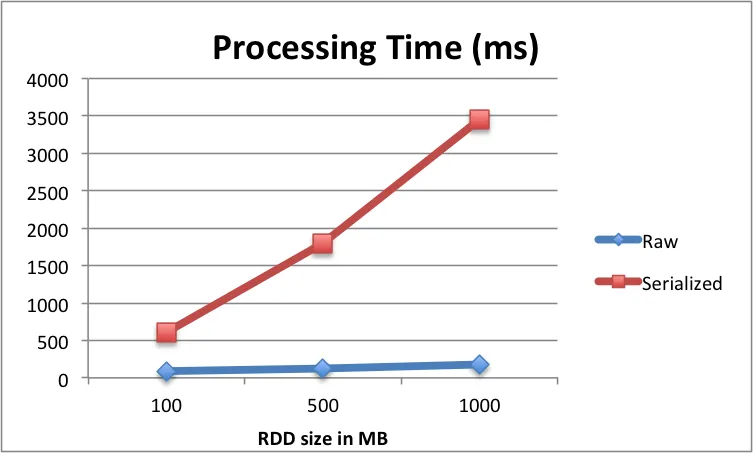
当我尝试使用cache()或persist(MEMORY_ONLY_SER())方法缓存我的RDD时,我的Spark集群会挂起。如果我不使用cache()方法,它可以在大约7分钟内计算出结果。
我有6个c3.xlarge EC2实例(每个实例4个核心,7.5 GB RAM),总共提供24个核心和37.7 GB内存。
我在主节点上使用以下命令运行应用程序:
SPARK_MEM=5g MEMORY_FRACTION="0.6" SPARK_HOME="/root/spark" java -cp ./uber-offline.jar:/root/spark/assembly/target/scala-2.10/spark-assembly_2.10-0.9.0-incubating-hadoop1.0.4.jar pl.instream.dsp.offline.OfflineAnalysis
数据集大小约为50GB,分成24个文件。我将其压缩并存储在S3存储桶中的24个文件中(每个文件大小为7MB到300MB)。
我绝对找不到我集群出现这种行为的原因,但似乎Spark消耗了所有可用内存并进入GC收集循环。当我查看GC详细信息时,我可以发现以下循环:
这最终导致消息变成这样:“
我有6个c3.xlarge EC2实例(每个实例4个核心,7.5 GB RAM),总共提供24个核心和37.7 GB内存。
我在主节点上使用以下命令运行应用程序:
SPARK_MEM=5g MEMORY_FRACTION="0.6" SPARK_HOME="/root/spark" java -cp ./uber-offline.jar:/root/spark/assembly/target/scala-2.10/spark-assembly_2.10-0.9.0-incubating-hadoop1.0.4.jar pl.instream.dsp.offline.OfflineAnalysis
数据集大小约为50GB,分成24个文件。我将其压缩并存储在S3存储桶中的24个文件中(每个文件大小为7MB到300MB)。
我绝对找不到我集群出现这种行为的原因,但似乎Spark消耗了所有可用内存并进入GC收集循环。当我查看GC详细信息时,我可以发现以下循环:
[GC 5208198K(5208832K), 0,2403780 secs]
[Full GC 5208831K->5208212K(5208832K), 9,8765730 secs]
[Full GC 5208829K->5208238K(5208832K), 9,7567820 secs]
[Full GC 5208829K->5208295K(5208832K), 9,7629460 secs]
[GC 5208301K(5208832K), 0,2403480 secs]
[Full GC 5208831K->5208344K(5208832K), 9,7497710 secs]
[Full GC 5208829K->5208366K(5208832K), 9,7542880 secs]
[Full GC 5208831K->5208415K(5208832K), 9,7574860 secs]
这最终导致消息变成这样:“
WARN storage.BlockManagerMasterActor: Removing BlockManager BlockManagerId(0, ip-xx-xx-xxx-xxx.eu-west-1.compute.internal, 60048, 0) with no recent heart beats: 64828ms exceeds 45000ms
...并且阻止计算机的任何进展。这看起来像是内存被100%消耗了,但我尝试使用更多RAM的机器(例如每台30GB),效果是相同的。
这种行为的原因可能是什么??有人可以帮忙吗?