我正在构建一个Spark应用程序,需要缓存约15GB的CSV文件。我在这里阅读了关于在Spark 1.6中引入的新的UnifiedMemoryManager:
https://0x0fff.com/spark-memory-management/
它还显示了这张图片:
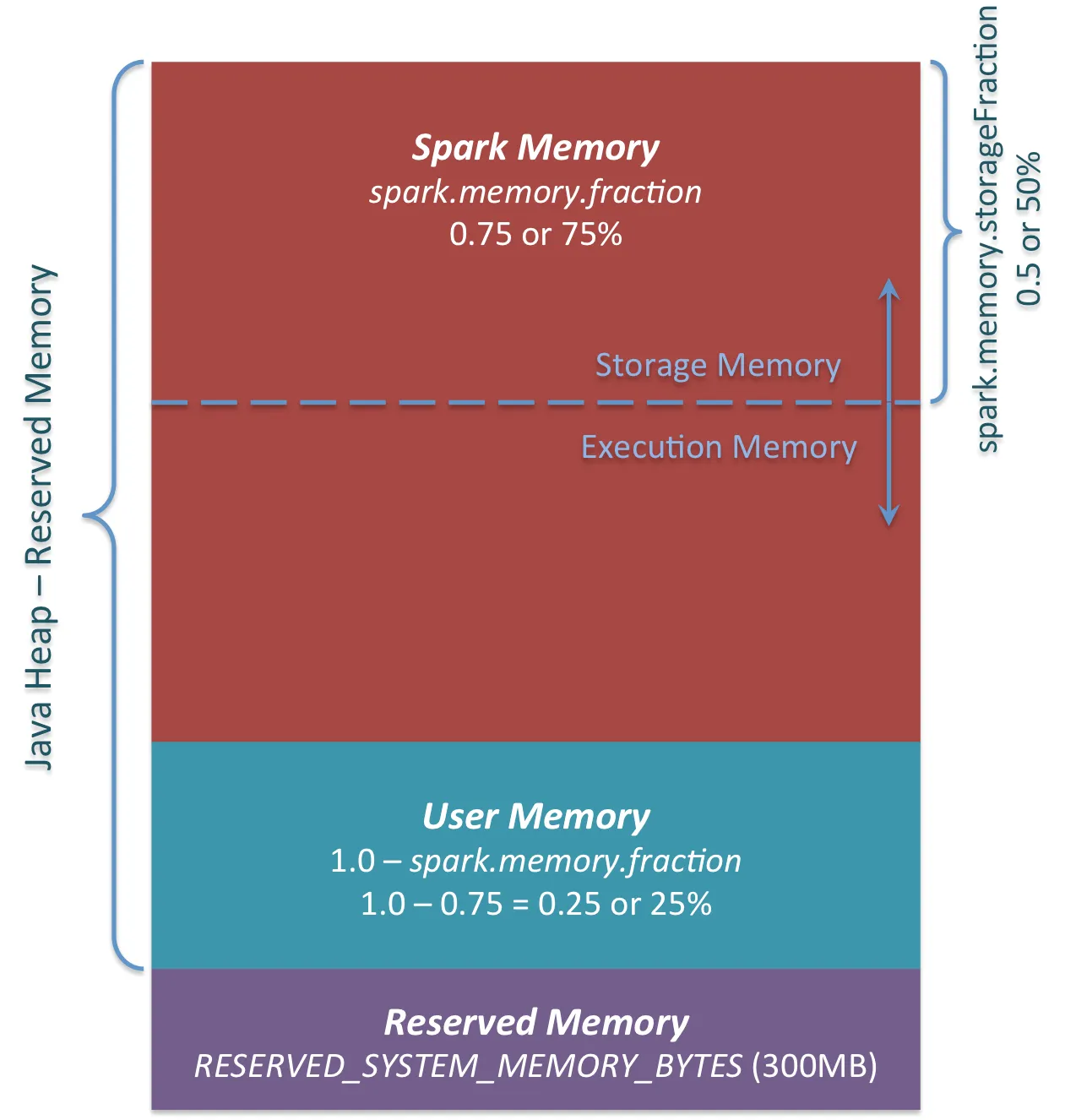
作者区分了User Memory和Spark Memory(后者又分为Storage和Execution Memory)。据我所知,Spark Memory可灵活用于执行(shuffle、sort等)和存储(缓存)操作-如果需要更多内存,则可以从另一部分(如果尚未完全使用)中使用。这个假设是正确的吗?
用户内存的描述如下:
用户内存。这是在分配Spark Memory之后保留下来的内存池,您完全可以按自己的意愿使用它。您可以在其中存储自己的数据结构,用于RDD转换。例如,您可以通过使用mapPartitions转换来重新编写Spark聚合,维护此聚合的哈希表,该哈希表会消耗所谓的用户内存。[...]再次声明,这是用户内存,您完全可以在其中存储什么数据以及如何存储,Spark不会对您的操作进行任何计算,也不关心您是否尊重此界限。如果您的代码不尊重此界限,可能会导致OOM错误。
我该如何访问这部分内存或者它是由Spark如何管理的?
对于我的目的,我只需要足够的Storage内存(因为我不做类似shuffle、join等的操作)吗?那么,我可以将spark.memory.storageFraction属性设置为1.0吗?
对我来说最重要的问题是,User Memory怎么样?特别是对于我上面描述的我的目的,它有什么用途?
当我更改程序以使用一些自己的类例如RDD<MyOwnRepresentationClass>而不是RDD<String>时,使用内存是否有区别?
以下是我的代码片段(从一个基准应用程序的Livy Client中多次调用它)。我使用带有Kryo序列化的Spark 1.6.2。
JavaRDD<String> inputRDD = sc.textFile(inputFile);
// Filter out invalid values
JavaRDD<String> cachedRDD = inputRDD.filter(new Function<String, Boolean>() {
@Override
public Boolean call(String row) throws Exception {
String[] parts = row.split(";");
// Some filtering stuff
return hasFailure;
}
}).persist(StorageLevel.MEMORY_ONLY_SER());