观看这个关于Spark内部的非常好的视频,演讲者说,除非在缓存RDD后执行操作,否则缓存不会真正发生。
在其他情况下,我从未看到count()被调用。因此,我猜他只在cache()之后调用count()来强制持久化在他所给出的简单示例中。在代码中每次调用cache()或persist()都不需要这样做。这是正确的吗?
观看这个关于Spark内部的非常好的视频,演讲者说,除非在缓存RDD后执行操作,否则缓存不会真正发生。
在其他情况下,我从未看到count()被调用。因此,我猜他只在cache()之后调用count()来强制持久化在他所给出的简单示例中。在代码中每次调用cache()或persist()都不需要这样做。这是正确的吗?
rdd.cache()
rdd.map(...).flatMap(...) //and so on
rdd.count() //or any other action
rdd.cache().count()
rdd.map(...).flatMap(...) //and so on
rdd.count() //or any other action
.cache()和.persist()都是转换操作(而不是动作),因此当您调用它们时,会将它们添加到DAG中。如下图所示,缓存/持久化的rdd/dataframe在点上呈绿色。
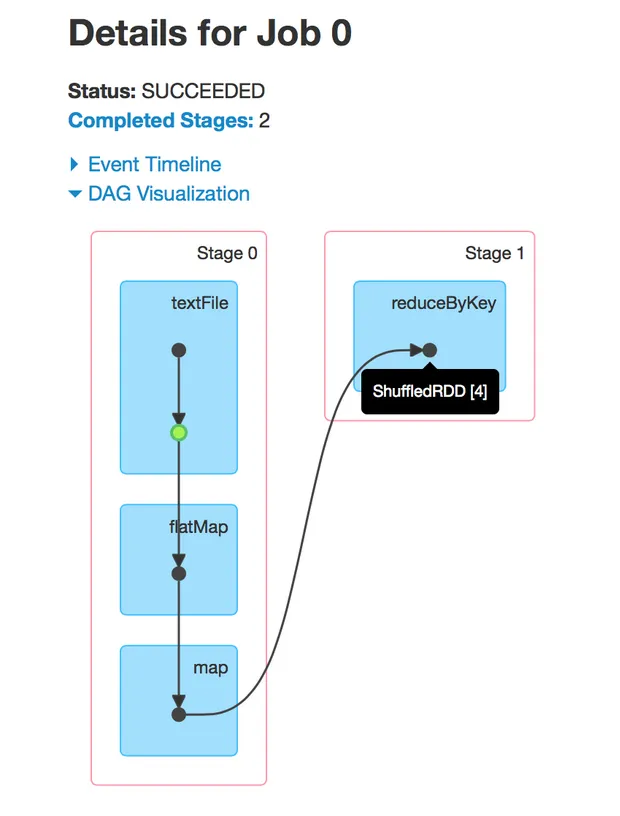
当您在许多转换后有一个动作(.count()、.save()、.show()等)时,立即执行另一个动作并不重要。
根据@code的示例:
// 1 CASE: cache/persist the initial rdd
rdd.cache()
rdd.count() // It forces the cache but it DOESNT need because we have the 2nd count.
rdd.map(...).flatMap(...) # Transformations
rdd.count() //or any other action
// 2 CASE: cache/persist the transformed rdd
rdd.map(...).flatMap(...) # Transformations
rdd.cache()
rdd.count() //or any other action
我的观点是,如果您不需要操作的结果,请勿强制进行缓存/持久化,因为这样会计算出一些无用的东西。
serverIPlist.par.map(copyDataToSolrFunction)。在这种情况下,我应该使用方法1还是方法2? - Aman Tandon