我想知道机器学习中的学习曲线是什么,绘制它的标准方式是什么?我的图应该有哪些x轴和y轴?
机器学习中的“学习曲线”是什么?
59
- Hossein
4
1从未听说过学习曲线。你是指ROC曲线吗?http://en.wikipedia.org/wiki/Receiver_operating_characteristic - Stompchicken
7不,学习曲线和ROC曲线不是同义词,正如我下面所描述的那样。 - MattBagg
@MattBagg:你说得完全正确,我回滚到编辑之前的版本了。 - Amro
请参阅《卷积神经网络架构的分析与优化》(https://arxiv.org/pdf/1707.09725.pdf#page=34)。 - Martin Thoma
10个回答
59
通常指的是预测准确性/误差与训练集大小之间的关系图(即:随着用于训练模型的实例数量的增加,模型在预测目标方面变得更好)。
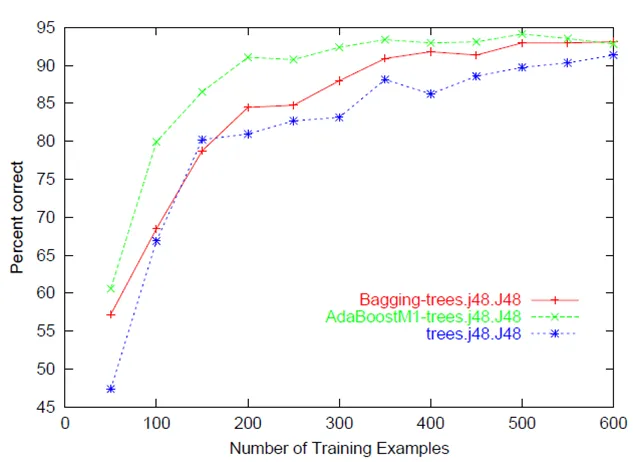
- Amro
5
2还有一篇更为新的文章:http://scikit-learn.org/stable/modules/learning_curve.html - The Disco Spider
Wikipedia条目提到了一种替代的学习曲线类型,即性能与迭代次数之间的关系。我对这两个定义有点困惑。对于性能-大小定义,对于每个训练大小
x,y轴值是从已经尽可能训练的模型中获得的(例如通过多次输入x样本直到收敛),还是仅使用一次x样本进行训练? - Jason继续上文:对于性能-迭代定义,对于随机训练来说,它必须是相当计算密集的,不是吗?因为对于每个输入样本,都必须预测所有训练样本并获得平均分数,然后它将与
n^2 成比例。 - Jason1性能-迭代:您在整个训练集上训练模型,并在当前模型的每次迭代中测量完整的训练/验证集上的损失函数。模型优化是迭代的,因此您让算法运行的时间越长,它就越有可能改进,我们使用这样的图来决定何时停止学习,因为模型收敛或变得过于敏感,从而失去了对验证集的泛化。 - Amro
1性能示例:您可以在不断增加的训练数据子集上训练模型,并绘制当前模型在完整的训练/验证集上测量的损失函数。通常情况下,每次都会训练模型直到收敛(使用相同的固定标准来确定收敛)。它可用于查找模型是否欠拟合(我们可以使用更多数据)或过拟合(我们需要调整正则化以提高泛化能力并减少对嘈杂的训练数据的敏感性)。 - Amro
34
我只是想简要指出一个旧问题,即学习曲线和ROC曲线不是同义词。如此问题中其他答案所示,传统上,学习曲线在另一个参数(水平轴上)发生变化时,通常描绘了垂直轴上的性能改进,例如训练集大小(在机器学习中)或迭代/时间(在机器和生物学习中)。一个显著的点是模型的许多参数在图中的不同点处都在发生变化。这里的其他答案已经很好地说明了学习曲线。
(还有工业制造业中学习曲线的另一种含义,起源于1930年代观察到随着制造的单位数量加倍,生产一个单独单位所需的劳动小时数以统一速率减少。虽然它并不真正相关,但为了完整起见并避免网络搜索的混淆而值得注意。)
相比之下,接收者操作特征曲线,或ROC曲线,不显示学习;它显示性能。 ROC曲线是分类器性能的图形表示,显示了在分类器的区分阈值变化时增加真阳性率(纵轴)和增加假阳性率(横轴)之间的权衡。因此,与模型相关的仅有一个参数(决策/区分阈值)在图中的不同点处会发生变化。此ROC曲线(来自维基百科链接)显示了三个不同分类器的性能。
{kind=link}
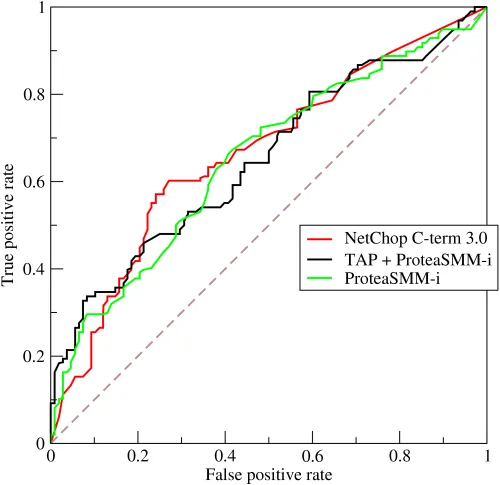
这里并没有展示学习过程,而是展示分类器在决策阈值变得更加宽松/严格时对两种不同成功/错误类别的性能。通过查看曲线下面积,我们可以看到分类器区分这两个类别的能力的整体指标。该曲线下面积度量单位对两个类别的成员数量不敏感,因此如果类别成员不平衡,则可能无法反映实际性能。ROC曲线有许多副标题,有兴趣的读者可以查看以下链接:
Fawcett, Tom. "ROC 图形: 研究人员的注意事项和实用考虑。" 机器学习 31 (2004): 1-38.
Swets, John A., Robyn M. Dawes, and John Monahan. "科学带来更好的决策。" Scientific American (2000): 83.
- MattBagg
17
有些人使用"学习曲线"来表示迭代过程的误差与迭代次数的关系,即它展示了某个效用函数的收敛情况。在下面的示例中,作者绘制了最小均方(LMS)算法的均方误差(MSE)作为迭代次数的函数。这说明了LMS算法学习频道脉冲响应的速度。
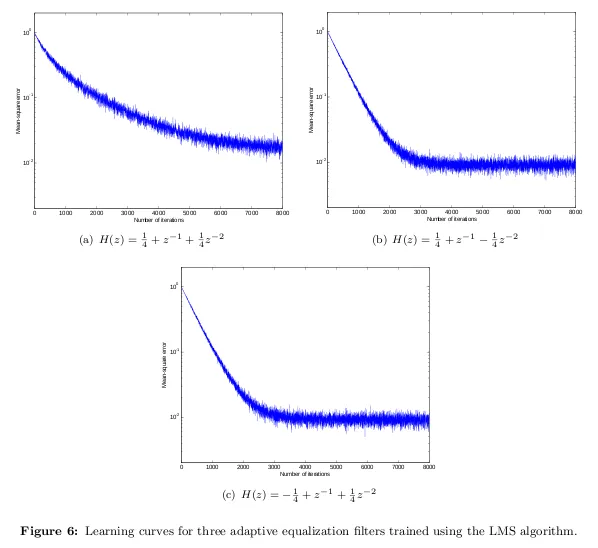
- Steve Tjoa
10
基本上,机器学习曲线可以帮助您找到算法开始学习的点。如果您取一条曲线并在它开始达到常数时切割一个斜率切线的导数,那么它开始建立学习能力。
根据您的x和y轴映射方式,其中一个轴将开始接近恒定值,而另一个轴的值将持续增加。这时您开始看到一些学习效果。整个曲线基本上允许您测量算法学习的速度。最大点通常是斜率开始减小的时候。您可以对最大/最小点进行多次导数测量。
因此,从以上例子中,您可以看到曲线逐渐趋向于一个恒定值。它最初通过训练示例来利用其学习,并且在最大/最小点处斜率扩大,从而越来越接近于恒定状态。此时,它能够从测试数据中获取新的示例,并从数据中找到新的独特结果。您会有关于迭代次数与误差的x/y轴测量数据。
- meme
4
如何确定给定模型是否需要更多训练点?一个有用的诊断工具是学习曲线。
• 预测准确性/误差与训练集大小的图表(即:随着用于训练的实例数量的增加,模型在预测目标方面变得更好)
• 学习曲线通常描述了垂直轴上的性能改进,当另一个参数(水平轴上)发生变化时,例如训练集大小(在机器学习中)或迭代/时间
• 学习曲线经常用于算法的健全性检查或提高性能
• 学习曲线绘制可以帮助诊断算法将遇到的问题
个人而言,以下两个链接帮助我更好地理解这个概念: 学习曲线 Sklearn学习曲线
• 预测准确性/误差与训练集大小的图表(即:随着用于训练的实例数量的增加,模型在预测目标方面变得更好)
• 学习曲线通常描述了垂直轴上的性能改进,当另一个参数(水平轴上)发生变化时,例如训练集大小(在机器学习中)或迭代/时间
• 学习曲线经常用于算法的健全性检查或提高性能
• 学习曲线绘制可以帮助诊断算法将遇到的问题
个人而言,以下两个链接帮助我更好地理解这个概念: 学习曲线 Sklearn学习曲线
- Aravind Krishnakumar
4
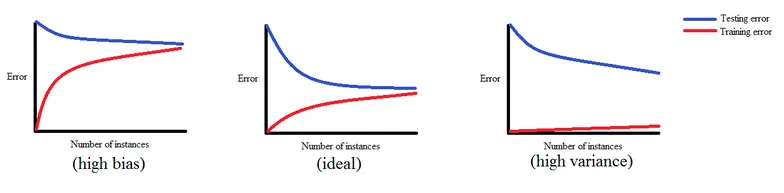
在安德鲁的机器学习课程中,学习曲线是训练/交叉验证误差与样本大小的图形。学习曲线可用于检测模型是否存在高偏差或高方差问题。如果模型存在高偏差问题,则随着样本数量的增加,训练误差将增加,交叉验证误差将减少,但最后它们仍将保持在一个高误差率上,同时也会出现高误差率的分类错误。对于高偏差问题,增加样本量不会有太大帮助。
如果模型存在高方差问题,则随着样本数量的增加,训练误差将持续增加,交叉验证误差将持续减少,并最终达到低训练和交叉验证误差率。因此,如果模型存在高方差问题,则增加样本量有助于提高模型的预测性能。
如果模型存在高方差问题,则随着样本数量的增加,训练误差将持续增加,交叉验证误差将持续减少,并最终达到低训练和交叉验证误差率。因此,如果模型存在高方差问题,则增加样本量有助于提高模型的预测性能。
- Emma Zhang
1
这是一张图表,比较了一个模型在不同数量的训练实例上准备和测试数据的表现,并且通常被用作机器学习中算法的分析工具,这些算法会逐步从训练数据集中学习。它可以帮助我们确定模型已经尽可能多地学习了有关数据的信息。
学习曲线有三种期望:
- 不良学习曲线:高偏差 - 不良学习曲线:高方差 - 理想学习曲线
学习曲线有三种期望:
- 不良学习曲线:高偏差 - 不良学习曲线:高方差 - 理想学习曲线
- Tidyquant
1
简单来说,学习曲线是一个图表,它将实例数量和指标(如损失或准确率)之间的关系表示出来。这个图表展示了随着经验的积累而学习的过程,因此被称为学习曲线。学习曲线在机器学习中被广泛应用于那些随着时间逐渐学习(优化其内部参数)的算法,例如深度学习神经网络。
- user13320096
1
使用此代码进行绘图:
# Loss Curves
plt.figure(figsize=[8,6])
plt.plot(history.history['loss'],'r',linewidth=3.0)
plt.plot(history.history['val_loss'],'b',linewidth=3.0)
plt.legend(['Training loss', 'Validation Loss'],fontsize=18)
plt.xlabel('Epochs ',fontsize=16)
plt.ylabel('Loss',fontsize=16)
plt.title('Loss Curves',fontsize=16)
# Accuracy Curves
plt.figure(figsize=[8,6])
plt.plot(history.history['acc'],'r',linewidth=3.0)
plt.plot(history.history['val_acc'],'b',linewidth=3.0)
plt.legend(['Training Accuracy', 'Validation Accuracy'],fontsize=18)
plt.xlabel('Epochs ',fontsize=16)
plt.ylabel('Accuracy',fontsize=16)
plt.title('Accuracy Curves',fontsize=16)
请注意:history = model.fit(...)
- Elie Sokhon
-3
示例 X=级别 y=薪水
X Y 0 2000 2 4000 4 6000 6 8000
回归给出了75%的准确度,这是一条直线
多项式给出了85%的准确度,因为有曲线
- Paritosh Yadav
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接