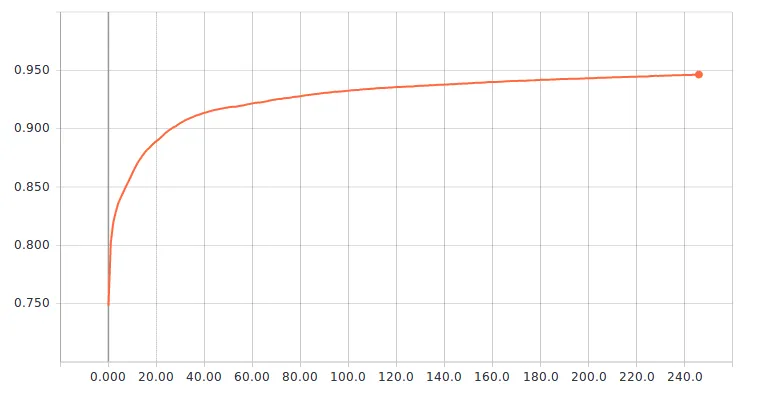
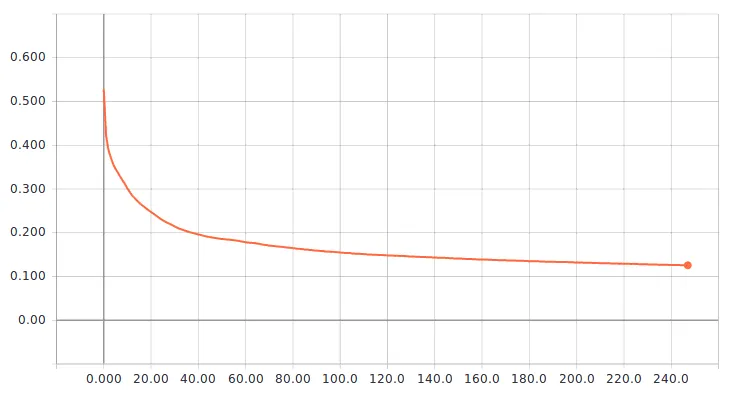
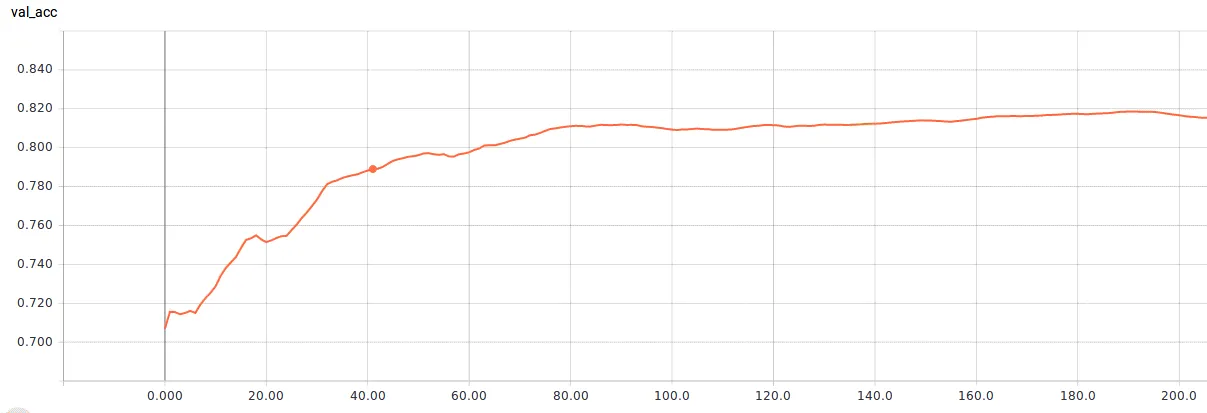
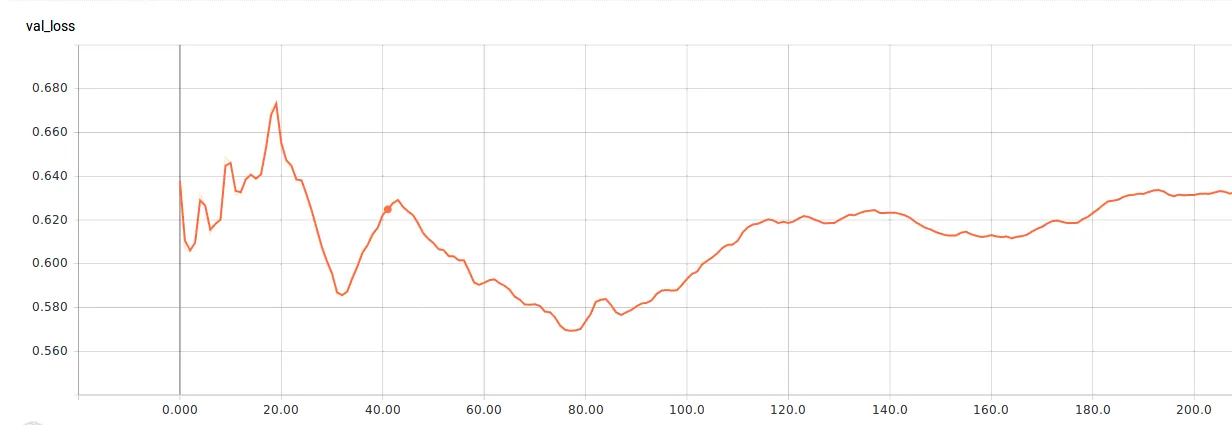
如何从训练/验证损失和准确率曲线中选择最佳模型?
3
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- spider
2
2请提供更多细节:您正在学习什么类型的数据(图像,序列)?您尝试分类多少类别?样本数量是否平衡或不平衡?您使用哪种架构?您使用哪种损失函数? - Chan Kha Vu
@FalconUA 感谢您的回复。我的问题是从卫星图像中识别云,因此我将问题转化为两类分割,一类是云,另一类是背景。数据集有8000个大小为256 * 256的4波段16位图像。架构是Segnet,损失函数是binary_crossentropy。样本不平衡,因为云覆盖相对于背景来说很小。 - spider
1个回答
3
首先,您需要根据开发/验证数据集的结果选择模型。因此,使用验证准确性和验证损失来评估模型的性能。
在某种程度上,更高的验证准确性通常与较低的验证损失相关。这是因为您的损失用于衡量预测结果与实际结果之间的差异。
不同的问题需要使用不同的指标进行衡量,就像我们通常在机器翻译中使用 BLEU 分数一样,您需要阅读一些关于您研究领域的论文,以了解哪种指标更受欢迎。
训练损失的减少和验证损失的增加在模型训练中是很正常的现象,通常意味着您的模型出现了过拟合。它只学习了出现在训练数据集中而不是整个数据集中的特征。
至于处理过拟合的方法,有许多方法,例如早期停止、删除层等。您可以通过谷歌搜索来了解更多信息。
在某种程度上,更高的验证准确性通常与较低的验证损失相关。这是因为您的损失用于衡量预测结果与实际结果之间的差异。
不同的问题需要使用不同的指标进行衡量,就像我们通常在机器翻译中使用 BLEU 分数一样,您需要阅读一些关于您研究领域的论文,以了解哪种指标更受欢迎。
训练损失的减少和验证损失的增加在模型训练中是很正常的现象,通常意味着您的模型出现了过拟合。它只学习了出现在训练数据集中而不是整个数据集中的特征。
至于处理过拟合的方法,有许多方法,例如早期停止、删除层等。您可以通过谷歌搜索来了解更多信息。
- Yutao ZHU
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接