请问您能指导我如何解释以下结果吗?
1)损失值小于验证损失值
2)损失值大于验证损失值
似乎在训练模型时,训练损失值应该始终小于验证损失值。但是,这两种情况都可能发生。
似乎在训练模型时,训练损失值应该始终小于验证损失值。但是,这两种情况都可能发生。
机器学习中真正的基本问题。
If validation loss >> training loss you can call it overfitting.
If validation loss > training loss you can call it some overfitting.
If validation loss < training loss you can call it some underfitting.
If validation loss << training loss you can call it underfitting.
您的目标是使验证损失尽可能低。有些过度拟合通常是件好事。最重要的是最终验证损失是否达到了最低点。
当训练损失较低时,这种情况经常发生。
另请查看如何防止过度拟合。
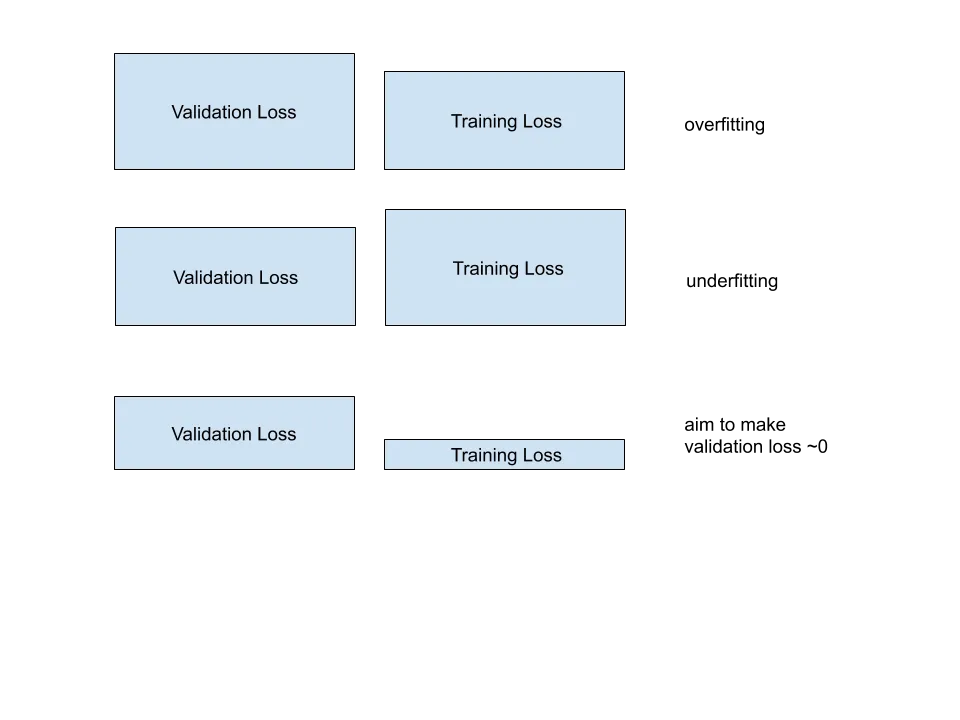
在机器学习和深度学习中,基本上有三种情况:
1)欠拟合
这是仅有的一种情况,其中损失值 > 验证损失值,但仅略高于后者。如果损失值远高于验证损失值,请发布您的代码和数据,以便我们查看。
2)过拟合
损失值 << 验证损失值
这意味着您的模型非常适配训练数据,但完全不适配验证数据,换句话说,它不能正确地推广到未见过的数据。
3)完美拟合
损失值 == 验证损失值
如果两个值最终大致相同,并且值正在收敛(随时间绘制损失),那么很有可能您做得很好。
1) 在训练数据上,您的模型表现比在未知验证数据上更好。略微过拟合是正常的,但高程度的过拟合需要使用压缩技术来确保泛化。
2) 您的模型在验证数据上表现更好。这可能是因为您在训练数据上使用了增强技术,使得预测与未修改的验证样本相比更难。也可能是因为您的训练损失是在一个epoch内计算的移动平均值,而验证损失是在同一epoch的学习阶段之后计算的。
Aurélien Geron发布了一篇关于这一现象的Twitter帖子。总结如下:
我用this essay的帮助回答了你的问题。
这可能有很多原因。
1:如果你使用正则化,正则化的数学公式会导致将权重加到损失上。因此,训练损失远高于验证损失。然而,在几次迭代后,训练和验证损失之间的差距会缩小。请注意,较低的损失并不一定意味着更高的准确性。
2:训练损失是在每个批次迭代期间每个时代计算的,但验证损失是在每个时代结束时计算的。这可能会使验证损失低于训练损失。但是,在许多迭代之后,验证损失超过训练损失。在这种情况下,较低的损失并不意味着更高的准确性。
3:另一个原因;数据集中存在噪声是不可避免的。有时我们的训练数据集包含比我们的验证数据集更多的异常值。因此,模型可以更容易地预测验证标签。在这种情况下,模型在验证方面既具有较低的损失又具有较高的准确性。
您可以在这里找到更详细的关于您问题的解释。