我正在使用Keras开发在线学习应用程序,通过model.train_on_batch(x_batch, y_batch)方法训练模型。我尝试增量添加训练数据,并绘制出测试和训练的损失情况。结果如下所示:
我的结果
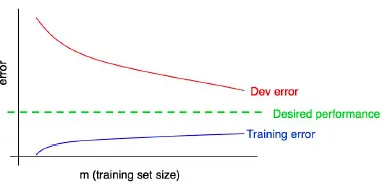
很高兴看到测试损失在减少,但是根据Andrew Ng的机器学习课程,如果我有一个像DNN这样强大的模型,随着逐渐添加更多训练数据,训练损失应该会增加,而测试损失应该会减少。所以,我真的很困惑。以下是他幻灯片的截图:
Andrew的幻灯片
当我逐渐添加更多的训练数据时,为什么训练损失和测试损失都会减少?
4
{kind=link}
{kind=link}
- Yongyao Jiang
7
1你在什么时候测量训练和测试损失?我不太清楚你的序数轴代表什么。 - Prune
不深入细节,这个想法是:安德鲁可能已经绘制了总误差,而您正在绘制平均值。 - Ladenkov Vladislav
序数轴是我逐步增加的训练大小。损失在每个训练阶段结束时进行测量。如果您愿意,可以在此处查看代码:https://github.com/stccenter/datadiscovery/blob/master/ranking/online_processing.py#L58 - Yongyao Jiang
准确性确实会提高,与损失相反。 - Yongyao Jiang
1@ClaudeCOULOMBE 有一段时间没联系了,但我认为这里的关键点是我发布的内容可以被视为SGD过程,这与Andrew在讲座中讨论的不同。更具体地说,Andrew在过度拟合训练数据后测量误差,然而我所做的只是使用新数据更新梯度(单次更新,不是Nilesh指出的过度拟合或完整训练)。我知道这很棘手,但你只需要考虑这些图表背后真正发生的事情。希望能有所帮助 :) - Yongyao Jiang
显示剩余2条评论
2个回答
2
正如我在Andrew Ng的机器学习课程中所学到的,如果我有一个像DNN这样强大的模型,那么随着我逐渐添加更多的训练数据,训练损失应该会增加,而测试损失应该会减少。
是的,这是正确的。假设您使用非常少的训练数据并使用一些强大的模型进行训练,在这种情况下,您的模型能够记住每个训练样本,并且模型设置将非常特定于训练数据,模型知道每个训练样本及其输出标签,因此训练损失将非常小。但是,相同的设置在测试数据上失败并产生糟糕的结果,这就是我们所说的过度拟合。
避免过度拟合的解决方案是:
- 增加训练数据:当您增加训练数据时,您的模型无法记住所有训练数据,但它将尝试找到适用于大多数训练数据的一些通用设置以在训练期间减少损失。但是,相同的通用设置也可以适用于预测测试数据。因此,通过增加训练数据,训练损失增加,但测试损失减少,这是预测所期望的结果。
- 减少模型复杂度:当您减少模型复杂度时,相同的情况也适用,您的模型无法记住所有训练数据。因此,训练损失增加,测试损失减少。
现在来看看您的问题。为什么这不适用于您的情况?
我坚信您绘制的图表是在训练阶段进行的。在神经网络设置中,模型的初始权重是随机设置的,因此它会在第一批上产生非常高的训练误差,并使用反向传播更新参数变量。现在,当它到达第二批时,模型已经学到了一些有关第一批训练数据的东西,因此第二批中的期望误差将略低。每个后续批次都会如此。您生成的图表是在模型训练期间,这就是我们在训练中看到的行为。
如果您想测试Andrew Ng的假设,则将您的训练数据分成1/4、1/2、..1.不同大小的集合。对每个数据集进行训练,直到您的训练损失降低。在最后一次迭代的结果中,您可以观察到具有较少训练样本的模型产生较低的训练误差和较高的测试误差,随着数据大小的增加,训练误差增加,但测试误差减少。
是的,这是正确的。假设您使用非常少的训练数据并使用一些强大的模型进行训练,在这种情况下,您的模型能够记住每个训练样本,并且模型设置将非常特定于训练数据,模型知道每个训练样本及其输出标签,因此训练损失将非常小。但是,相同的设置在测试数据上失败并产生糟糕的结果,这就是我们所说的过度拟合。
避免过度拟合的解决方案是:
- 增加训练数据:当您增加训练数据时,您的模型无法记住所有训练数据,但它将尝试找到适用于大多数训练数据的一些通用设置以在训练期间减少损失。但是,相同的通用设置也可以适用于预测测试数据。因此,通过增加训练数据,训练损失增加,但测试损失减少,这是预测所期望的结果。
- 减少模型复杂度:当您减少模型复杂度时,相同的情况也适用,您的模型无法记住所有训练数据。因此,训练损失增加,测试损失减少。
现在来看看您的问题。为什么这不适用于您的情况?
我坚信您绘制的图表是在训练阶段进行的。在神经网络设置中,模型的初始权重是随机设置的,因此它会在第一批上产生非常高的训练误差,并使用反向传播更新参数变量。现在,当它到达第二批时,模型已经学到了一些有关第一批训练数据的东西,因此第二批中的期望误差将略低。每个后续批次都会如此。您生成的图表是在模型训练期间,这就是我们在训练中看到的行为。
如果您想测试Andrew Ng的假设,则将您的训练数据分成1/4、1/2、..1.不同大小的集合。对每个数据集进行训练,直到您的训练损失降低。在最后一次迭代的结果中,您可以观察到具有较少训练样本的模型产生较低的训练误差和较高的测试误差,随着数据大小的增加,训练误差增加,但测试误差减少。
- Nilesh Birari
2
如果我理解正确的话,你是在说安德鲁的假设与 SGD 无关? - Yongyao Jiang
不,这与 SGD 无关。如果你增加训练数据的大小,那么在完全训练后,你的训练损失会增加,而测试损失会减少。 - Nilesh Birari
0
我真的很困惑...我学习并观察到,训练损失/误差随训练数据大小增加而增加,正如吴恩达博士的机器学习课程所述。
最近我也遇到了这个异常情况。训练损失和验证损失曲线在训练数据量增加的同时都在下降。代码是在所有训练完成后才进行绘图的。实际上,我已经根据Nilesh Birari的建议使用不断增加的数据量训练了10个不同的深度神经网络模型。
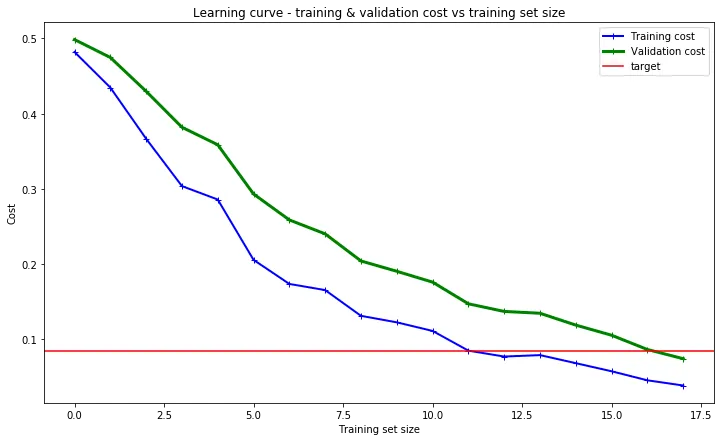
我怀疑吴恩达博士的图表假设数据点数量已经相当大。该图表未显示小型训练集的训练误差曲线。也许在这个领域,对于高容量的深度神经网络,随着训练数据量的增加,训练损失和验证损失都可以同时减少。
话虽如此,我用相同的代码但不同的数据,在小型经典机器学习模型中得到了吴恩达博士所描述的行为,我只需要更换模型。
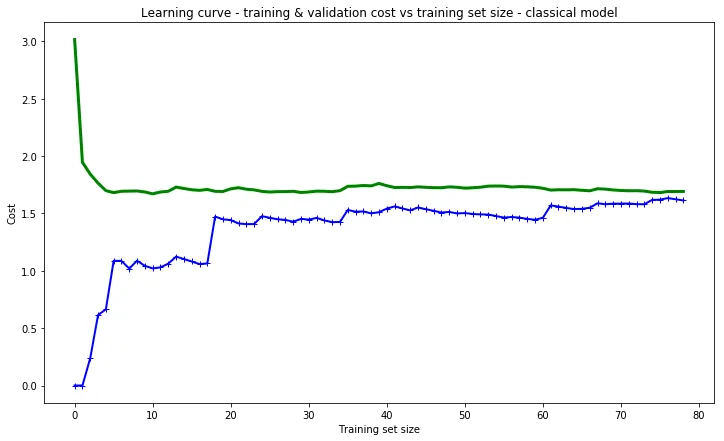
- Claude COULOMBE
1
答案,就像机器学习中经常出现的那样,就在数据中。检查我的数据后,我发现它们是有序的,但我确信情况并非如此。因此,关键点是我们应该始终对数据进行洗牌,但保持输入和标签相关联。这是37个神经网络无法正常工作的原因中的第7点。 - Claude COULOMBE
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接