我知道这个问题有点老了,但出于好奇和训练目的,我使用了JMH进行了一些测试。结果略有不同:
- 按位或(
a | b != 0)和乘法(a * b != 0)速度最快;
- 普通与运算(
a!=0 & b!=0)几乎和乘法一样快;
- 短路与与短路或(
a!=0 && b!=0、!(a!=0 || b!=0))速度最慢。
免责声明:我甚至不是JMH的专家。
以下是代码,我尝试复制了问题中发布的代码,并添加了按位或操作:
@Warmup(iterations = 5, time = 100, timeUnit = TimeUnit.MILLISECONDS)
@Measurement(iterations = 10, time = 100, timeUnit = TimeUnit.MILLISECONDS)
@Fork(value = 3)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
@State(Scope.Benchmark)
public class MultAnd {
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(MultAnd.class.getSimpleName())
.build();
new Runner(opt).run();
}
private static final int size = 50_000_000;
@Param({"0.00", "0.10", "0.20", "0.30", "0.40", "0.45",
"0.50", "0.55", "0.60", "0.70", "0.80", "0.90",
"1.00"})
private double fraction;
private int[][] nums;
@Setup
public void setup() {
nums = new int[2][size];
for(int i = 0 ; i < 2 ; i++) {
for(int j = 0 ; j < size ; j++) {
double random = Math.random();
if (random < fraction)
nums[i][j] = 0;
else
nums[i][j] = (int) (random*15 + 1);
}
}
}
@Benchmark
public int and() {
int s = 0;
for (int i = 0; i < size; i++) {
if ((nums[0][i]!=0) & (nums[1][i]!=0))
s++;
}
return s;
}
@Benchmark
public int andAnd() {
int s = 0;
for (int i = 0; i < size; i++) {
if ((nums[0][i]!=0) && (nums[1][i]!=0))
s++;
}
return s;
}
@Benchmark
public int bitOr() {
int s = 0;
for (int i = 0; i < size; i++) {
if ((nums[0][i] | nums[1][i]) != 0)
s++;
}
return s;
}
@Benchmark
public int mult() {
int s = 0;
for (int i = 0; i < size; i++) {
if (nums[0][i]*nums[1][i] != 0)
s++;
}
return s;
}
@Benchmark
public int notOrOr() {
int s = 0;
for (int i = 0; i < size; i++) {
if (!((nums[0][i]!=0) || (nums[1][i]!=0)))
s++;
}
return s;
}
}
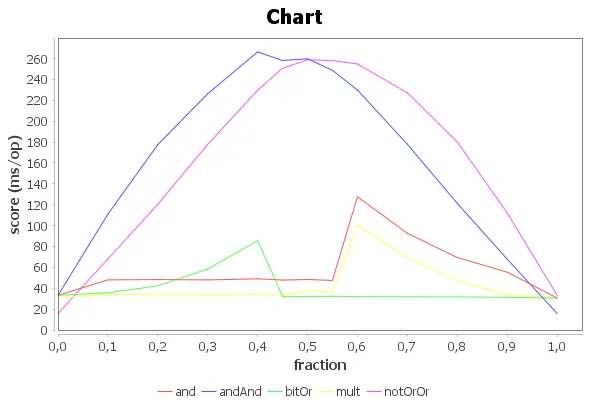
结果如下:
REMEMBER: The numbers below are just data. To gain reusable insights, you need to follow up on
why the numbers are the way they are. Use profilers (see -prof, -lprof), design factorial
experiments, perform baseline and negative tests that provide experimental control, make sure
the benchmarking environment is safe on JVM/OS/HW level, ask for reviews from the domain experts.
Do not assume the numbers tell you what you want them to tell.
Benchmark (fraction) Mode Cnt Score Error Units
MultAnd.and 0.00 avgt 30 33.238 ± 0.883 ms/op
MultAnd.and 0.10 avgt 30 48.011 ± 1.635 ms/op
MultAnd.and 0.20 avgt 30 48.284 ± 1.797 ms/op
MultAnd.and 0.30 avgt 30 47.969 ± 1.463 ms/op
MultAnd.and 0.40 avgt 30 48.999 ± 2.881 ms/op
MultAnd.and 0.45 avgt 30 47.804 ± 1.053 ms/op
MultAnd.and 0.50 avgt 30 48.332 ± 1.990 ms/op
MultAnd.and 0.55 avgt 30 47.457 ± 1.210 ms/op
MultAnd.and 0.60 avgt 30 127.530 ± 3.104 ms/op
MultAnd.and 0.70 avgt 30 92.630 ± 1.471 ms/op
MultAnd.and 0.80 avgt 30 69.458 ± 1.609 ms/op
MultAnd.and 0.90 avgt 30 55.421 ± 1.443 ms/op
MultAnd.and 1.00 avgt 30 30.672 ± 1.387 ms/op
MultAnd.andAnd 0.00 avgt 30 33.187 ± 0.978 ms/op
MultAnd.andAnd 0.10 avgt 30 110.943 ± 1.435 ms/op
MultAnd.andAnd 0.20 avgt 30 177.527 ± 2.353 ms/op
MultAnd.andAnd 0.30 avgt 30 226.247 ± 1.879 ms/op
MultAnd.andAnd 0.40 avgt 30 266.316 ± 18.647 ms/op
MultAnd.andAnd 0.45 avgt 30 258.120 ± 2.638 ms/op
MultAnd.andAnd 0.50 avgt 30 259.727 ± 3.532 ms/op
MultAnd.andAnd 0.55 avgt 30 248.706 ± 1.419 ms/op
MultAnd.andAnd 0.60 avgt 30 229.825 ± 1.256 ms/op
MultAnd.andAnd 0.70 avgt 30 177.911 ± 2.787 ms/op
MultAnd.andAnd 0.80 avgt 30 121.303 ± 2.724 ms/op
MultAnd.andAnd 0.90 avgt 30 67.914 ± 1.589 ms/op
MultAnd.andAnd 1.00 avgt 30 15.892 ± 0.349 ms/op
MultAnd.bitOr 0.00 avgt 30 33.271 ± 1.896 ms/op
MultAnd.bitOr 0.10 avgt 30 35.597 ± 1.536 ms/op
MultAnd.bitOr 0.20 avgt 30 42.366 ± 1.641 ms/op
MultAnd.bitOr 0.30 avgt 30 58.385 ± 0.778 ms/op
MultAnd.bitOr 0.40 avgt 30 85.567 ± 1.678 ms/op
MultAnd.bitOr 0.45 avgt 30 32.152 ± 1.345 ms/op
MultAnd.bitOr 0.50 avgt 30 32.190 ± 1.357 ms/op
MultAnd.bitOr 0.55 avgt 30 32.335 ± 1.384 ms/op
MultAnd.bitOr 0.60 avgt 30 31.910 ± 1.026 ms/op
MultAnd.bitOr 0.70 avgt 30 31.783 ± 0.807 ms/op
MultAnd.bitOr 0.80 avgt 30 31.671 ± 0.745 ms/op
MultAnd.bitOr 0.90 avgt 30 31.329 ± 0.708 ms/op
MultAnd.bitOr 1.00 avgt 30 30.530 ± 0.534 ms/op
MultAnd.mult 0.00 avgt 30 30.859 ± 0.735 ms/op
MultAnd.mult 0.10 avgt 30 33.933 ± 0.887 ms/op
MultAnd.mult 0.20 avgt 30 34.243 ± 0.917 ms/op
MultAnd.mult 0.30 avgt 30 33.825 ± 1.155 ms/op
MultAnd.mult 0.40 avgt 30 34.309 ± 1.334 ms/op
MultAnd.mult 0.45 avgt 30 33.709 ± 1.277 ms/op
MultAnd.mult 0.50 avgt 30 37.699 ± 4.029 ms/op
MultAnd.mult 0.55 avgt 30 36.374 ± 2.948 ms/op
MultAnd.mult 0.60 avgt 30 100.354 ± 1.553 ms/op
MultAnd.mult 0.70 avgt 30 69.570 ± 1.441 ms/op
MultAnd.mult 0.80 avgt 30 47.181 ± 1.567 ms/op
MultAnd.mult 0.90 avgt 30 33.552 ± 0.999 ms/op
MultAnd.mult 1.00 avgt 30 30.775 ± 0.548 ms/op
MultAnd.notOrOr 0.00 avgt 30 15.701 ± 0.254 ms/op
MultAnd.notOrOr 0.10 avgt 30 68.052 ± 1.433 ms/op
MultAnd.notOrOr 0.20 avgt 30 120.393 ± 2.299 ms/op
MultAnd.notOrOr 0.30 avgt 30 177.729 ± 2.438 ms/op
MultAnd.notOrOr 0.40 avgt 30 229.547 ± 1.859 ms/op
MultAnd.notOrOr 0.45 avgt 30 250.660 ± 4.810 ms/op
MultAnd.notOrOr 0.50 avgt 30 258.760 ± 2.190 ms/op
MultAnd.notOrOr 0.55 avgt 30 258.010 ± 1.018 ms/op
MultAnd.notOrOr 0.60 avgt 30 254.732 ± 2.076 ms/op
MultAnd.notOrOr 0.70 avgt 30 227.148 ± 2.040 ms/op
MultAnd.notOrOr 0.80 avgt 30 180.193 ± 4.659 ms/op
MultAnd.notOrOr 0.90 avgt 30 112.212 ± 3.111 ms/op
MultAnd.notOrOr 1.00 avgt 30 33.458 ± 0.952 ms/op
或者以图表形式呈现:
!(a == 0 || b == 0)怎么办?微基准测试极不可靠,这很难真正测量出来(大约3%听起来像是误差范围)。 - Elliott Frischa != 0 & b != 0。 - Louis Wassermana*b!= 0少了一个分支。 - Erwin Bolwidt(1<<16) * (1<<16) == 0,但它们都不等于零。 - CodesInChaosaе’ҢbдёӯжңүдёҖдёӘдёәйӣ¶пјҢеҲҷa*bз»“жһңдёәйӣ¶пјӣеҸӘжңүеҪ“дёӨиҖ…йғҪдёәйӣ¶ж—¶пјҢa|bз»“жһңжүҚдёәйӣ¶гҖӮ - hmakholm left over Monica