我正在阅读Fedor Pikus的这本书,他有一些非常非常有趣的例子,对我来说是一个惊喜。
特别是这个基准测试,其中唯一的区别在于,在其中一个中我们在if中使用||,而在另一个中我们使用|。
void BM_misspredict(benchmark::State& state)
{
std::srand(1);
const unsigned int N = 10000;;
std::vector<unsigned long> v1(N), v2(N);
std::vector<int> c1(N), c2(N);
for (int i = 0; i < N; ++i)
{
v1[i] = rand();
v2[i] = rand();
c1[i] = rand() & 0x1;
c2[i] = !c1[i];
}
unsigned long* p1 = v1.data();
unsigned long* p2 = v2.data();
int* b1 = c1.data();
int* b2 = c2.data();
for (auto _ : state)
{
unsigned long a1 = 0, a2 = 0;
for (size_t i = 0; i < N; ++i)
{
if (b1[i] || b2[i]) // Only difference
{
a1 += p1[i];
}
else
{
a2 *= p2[i];
}
}
benchmark::DoNotOptimize(a1);
benchmark::DoNotOptimize(a2);
benchmark::ClobberMemory();
}
state.SetItemsProcessed(state.iterations());
}
void BM_predict(benchmark::State& state)
{
std::srand(1);
const unsigned int N = 10000;;
std::vector<unsigned long> v1(N), v2(N);
std::vector<int> c1(N), c2(N);
for (int i = 0; i < N; ++i)
{
v1[i] = rand();
v2[i] = rand();
c1[i] = rand() & 0x1;
c2[i] = !c1[i];
}
unsigned long* p1 = v1.data();
unsigned long* p2 = v2.data();
int* b1 = c1.data();
int* b2 = c2.data();
for (auto _ : state)
{
unsigned long a1 = 0, a2 = 0;
for (size_t i = 0; i < N; ++i)
{
if (b1[i] | b2[i]) // Only difference
{
a1 += p1[i];
}
else
{
a2 *= p2[i];
}
}
benchmark::DoNotOptimize(a1);
benchmark::DoNotOptimize(a2);
benchmark::ClobberMemory();
}
state.SetItemsProcessed(state.iterations());
}
我不会详细解释书中为什么后者更快,但是基本思路是硬件分支预测器在较慢的版本和 |(按位或)版本中有2次错判的机会。请参见下面的基准测试结果。
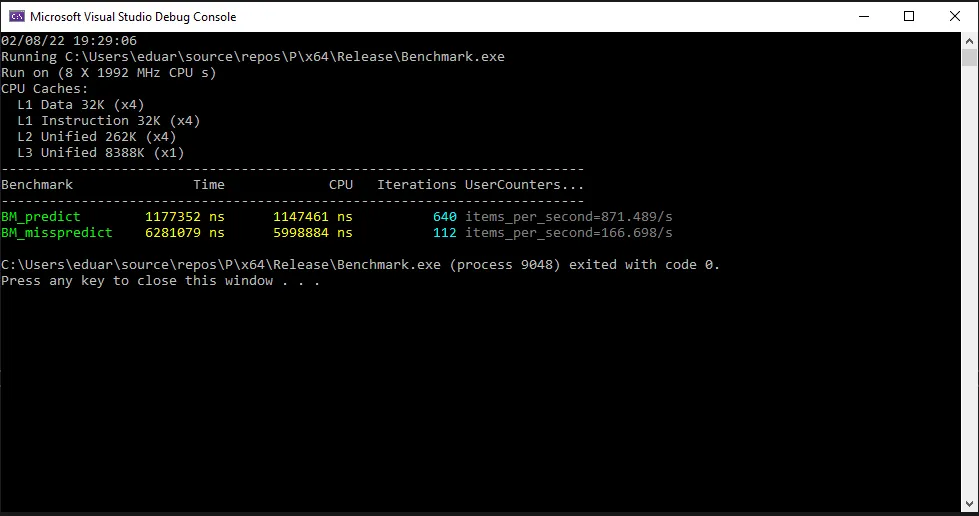
那么问题来了,为什么我们不总是在分支中使用 | 而不是 ||?
|,那么它看起来就像一个 bug。现在你必须花费时间说服同事(甚至是你自己),使用|的“技巧”是有效的。 - PaulMcKenzie1 | DropTheBomb()与true || DropTheBomb()进行比较... - user1196549b1[i] || b2[i]在这种情况下优化成一个or指令。虽然int* b2 = c2.data()已经在此函数内部的初始化部分中被引用过了,但证明这一点需要很多工作。(并且在其他情况下,可能会出现缓存未命中的情况。) - Peter Cordes|和||是等效的(除了短路);但这是不正确的,因为(例如)printA_then_returnZero() || printB_then_returnZero()必须总是打印AB,但是printA_then_returnZero() | printB_then_returnZero()可以打印AB或BA。 - psmears