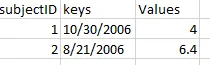我有一个输入数据框,可以通过以下代码生成
df = pd.DataFrame({'subjectID' :[1,1,2,2],'keys':
['H1Date','H1','H2Date','H2'],'Values':
['10/30/2006',4,'8/21/2006',6.4]})
输入的数据框如下所示:
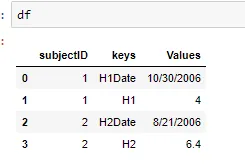
s1 = df.set_index('subjectID').stack().reset_index()
s1.rename(columns={0:'values'},
inplace=True)
d1 = s1[s1['level_1'].str.contains('Date')]
d2 = s1[~s1['level_1'].str.contains('Date')]
d1['g'] = d1.groupby('subjectID').cumcount()
d2['g'] = d2.groupby('subjectID').cumcount()
d3 = pd.merge(d1,d2,on=["subjectID", 'g'],how='left').drop(['g','level_1_x','level_1_y'], axis=1)
虽然这个方法可以工作,但我担心这可能不是最好的方法。因为我们可能有超过200列和50k条记录。如果有任何帮助来进一步改善我的代码,将非常有用。
我希望输出的数据框看起来像下面显示的那样