我希望用Scikit绘制训练和验证集的损失曲线,就像Keras一样。我选择了一个具体的回归问题数据集,该数据集可在以下位置找到:
http://archive.ics.uci.edu/ml/machine-learning-databases/concrete/compressive/
所以,我已经将数据转换为CSV格式,我的程序的第一个版本如下: 模型1df=pd.read_csv("Concrete_Data.csv")
train,validate,test=np.split(df.sample(frac=1),[int(.8*len(df)),int(.90*len(df))])
Xtrain=train.drop(["ConcreteCompStrength"],axis="columns")
ytrain=train["ConcreteCompStrength"]
Xval=validate.drop(["ConcreteCompStrength"],axis="columns")
yval=validate["ConcreteCompStrength"]
mlp=MLPRegressor(activation="relu",max_iter=5000,solver="adam",random_state=2)
mlp.fit(Xtrain,ytrain)
plt.plot(mlp.loss_curve_,label="train")
mlp.fit(Xval,yval) #doubt
plt.plot(mlp.loss_curve_,label="validation") #doubt
plt.legend()
生成的图表如下:
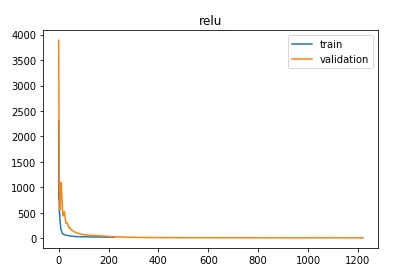
第二个模型:
在这个模型中,我尝试使用验证分数如下:
df=pd.read_csv("Concrete_Data.csv")
train,validate,test=np.split(df.sample(frac=1),[int(.8*len(df)),int(.90*len(df))])
Xtrain=train.drop(["ConcreteCompStrength"],axis="columns")
ytrain=train["ConcreteCompStrength"]
Xval=validate.drop(["ConcreteCompStrength"],axis="columns")
yval=validate["ConcreteCompStrength"]
mlp=MLPRegressor(activation="relu",max_iter=5000,solver="adam",random_state=2,early_stopping=True)
mlp.fit(Xtrain,ytrain)
plt.plot(mlp.loss_curve_,label="train")
plt.plot(mlp.validation_scores_,label="validation") #line changed
plt.legend()
对于这个模型,我必须将早停止的部分设置为true,并且要绘制验证分数,但是图形结果有点奇怪:
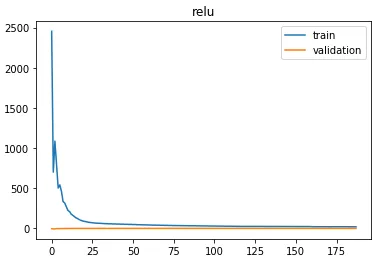
在Scikit中,调整超参数的正确方法是如何绘制这些损失曲线?
更新:我已经按照建议编写了模块,如下所示:
mlp=MLPRegressor(activation="relu",max_iter=1,solver="adam",random_state=2,early_stopping=True)
training_mse = []
validation_mse = []
epochs = 5000
for epoch in range(1,epochs):
mlp.fit(X_train, Y_train)
Y_pred = mlp.predict(X_train)
curr_train_score = mean_squared_error(Y_train, Y_pred) # training performances
Y_pred = mlp.predict(X_valid)
curr_valid_score = mean_squared_error(Y_valid, Y_pred) # validation performances
training_mse.append(curr_train_score) # list of training perf to plot
validation_mse.append(curr_valid_score) # list of valid perf to plot
plt.plot(training_mse,label="train")
plt.plot(validation_mse,label="validation")
plt.legend()
但所得的图形是两条平直的线:
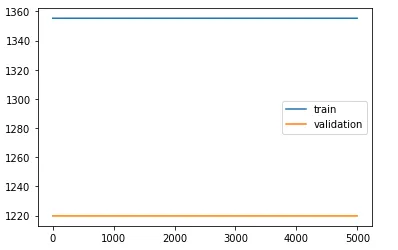
这里似乎有些东西我没搞明白。
{kind=link}