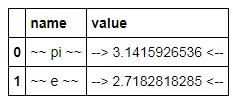
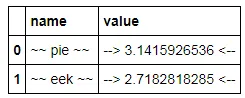
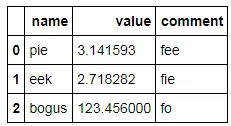
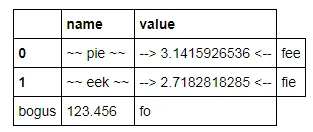
我想使用 print() 和 IPython display() 来展示一个给定格式的 pandas dataframe。例如:
df = pd.DataFrame([123.4567, 234.5678, 345.6789, 456.7890],
index=['foo','bar','baz','quux'],
columns=['cost'])
print df
cost
foo 123.4567
bar 234.5678
baz 345.6789
quux 456.7890
我希望以某种方式迫使它打印
cost
foo $123.46
bar $234.57
baz $345.68
quux $456.79
如何做到这一点?无需修改数据本身或创建副本,只需更改其显示方式。