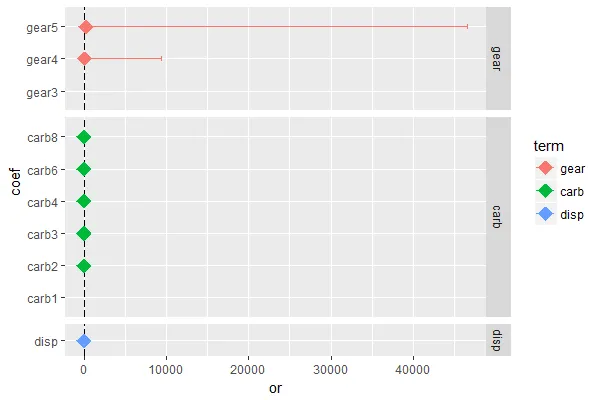
我想使用ggplot2包制作森林图,并且我对我的输出感到满意(见下面的森林图)。
该图显示了回归模型中给定变量的水平(比率比和置信区间),以及参考水平。
问题是生成图需要大量的手动劳动。
第一个问题是,我希望参考水平在图中跟随给定变量的其他水平,所以我手动输入了每个这样的参考水平(请参见下表)。为使ggplot2正常工作,我输入了任意负的比率比和置信区间值作为参考水平,然后将绘图限制设置为从零到较大的正数范围。
第二个问题是,因为我的原始变量位于单个列中,所以我手动输入颜色,这很耗时。
是否有更简单的方法生成这样的图?任何帮助都将不胜感激。
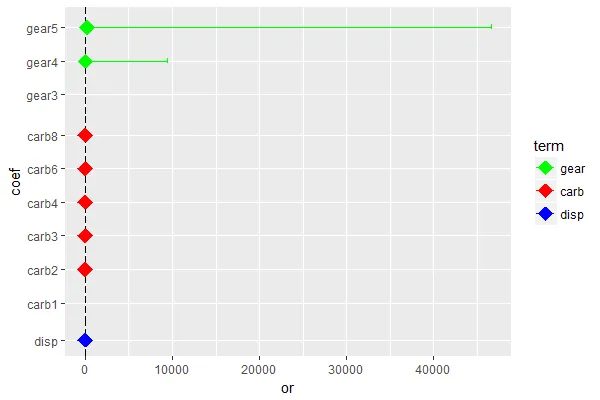
该图显示了回归模型中给定变量的水平(比率比和置信区间),以及参考水平。
问题是生成图需要大量的手动劳动。
第一个问题是,我希望参考水平在图中跟随给定变量的其他水平,所以我手动输入了每个这样的参考水平(请参见下表)。为使ggplot2正常工作,我输入了任意负的比率比和置信区间值作为参考水平,然后将绘图限制设置为从零到较大的正数范围。
第二个问题是,因为我的原始变量位于单个列中,所以我手动输入颜色,这很耗时。
是否有更简单的方法生成这样的图?任何帮助都将不胜感激。
# DATA
mtcars
mtcars$gear <- as.factor(mtcars$gear)
mtcars$carb <- as.factor(mtcars$carb)
# PREPARE ODDS RATIO & CONFIDENCE INTERVALS DATA FRAME
model = lm(mpg ~ gear + carb + disp, data = mtcars ) # make regression model
forest_table = data.frame(
or= round(exp(coef(model)),2),
round(exp(confint(model, level = 0.95)),2),
check.names = F) # make a table with odds ratio and confidence intervals
names(forest_table) = c("or", "ci_lb", "ci_ub") # give columns clear names
library(data.table)
setDT(forest_table, keep.rownames = TRUE)[] # turn row names into a column
forest_table <- as.data.frame(forest_table) # turn table into a data frame
forest_table <- forest_table[-1, ] # get rid of the intercept row
# ADD ROWS WITH REFERENCE LEVELS TO PREPARED DATA FRAME
r <- 2 # row after which new row is to be inserted
newrow <- c("3 reference", -10.00, -9.00, -11.00) # row to be inserted
forest_table <- rbind(forest_table[1:r, ], newrow, forest_table[-(1:r), ]) # insert row
r <- 8 # row after which new row is to be inserted
newrow <- c("1 reference", -10.00, -9.00, -11.00) # row to be inserted
forest_table <- rbind(forest_table[1:r, ], newrow, forest_table[-(1:r), ]) # insert row
# FIX CLASSES IN PREPARED DATA FRAME
forest_table$or <- as.numeric(forest_table$or)
forest_table$ci_lb <- as.numeric(forest_table$ci_lb)
forest_table$ci_ub <- as.numeric(forest_table$ci_ub)
# ADD DUMMY VARIABLE TO CONTROL ORDER IN PLOT
forest_table$order <- as.factor(rep(c(1, 2, 3, 4, 5, 6, 7, 8, 9, 10))) # create dummy variable
forest_table$order <- factor(forest_table$order,
levels = rev(levels(forest_table$order)))
# use dummy variable to counteract ggplot2 default of reversing the order of levels in
# the prepared data frame when plotting
# PLOT
library(ggplot2)
forestplot <- ggplot(forest_table, aes(or, order)) +
geom_point(size = 5, shape = 18, aes(colour = order)) + # data points
geom_errorbarh(aes(xmax = ci_ub, xmin = ci_lb, colour = order),
height = 0.15) + # error bars
geom_vline(xintercept = 1, linetype = "longdash") + # line marking 0 on x axis
scale_x_continuous(breaks = seq(0, 40000, 10000),
labels = seq(0, 40000, 10000),
limits = c(0, 50000)) + # x axis scale and labels
scale_colour_manual(values = c("blue", "red", "red", "red", "red", "red", "red",
"green", "green", "green")) # manually set one colour per variable