我看到:
这些与原生 Python 有关,而不是 pandas。
如果我有以下系列:
ix num
0 1
1 6
2 4
3 5
4 2
如果在序列中找到3,则返回3的索引;如果未在序列中找到3,则返回3下面和上面值的索引。
例如,在序列 {1,6,4,5,2} 中输入 3,应该得到值为 (4,2),索引为 (2,4)。
我看到:
这些与原生 Python 有关,而不是 pandas。
如果我有以下系列:
ix num
0 1
1 6
2 4
3 5
4 2
如果在序列中找到3,则返回3的索引;如果未在序列中找到3,则返回3下面和上面值的索引。
例如,在序列 {1,6,4,5,2} 中输入 3,应该得到值为 (4,2),索引为 (2,4)。
argsort(),例如:input = 3。In [198]: input = 3
In [199]: df.iloc[(df['num']-input).abs().argsort()[:2]]
Out[199]:
num
2 4
4 2
df_sort 是包含两个最接近数值的数据框。
In [200]: df_sort = df.iloc[(df['num']-input).abs().argsort()[:2]]
对于索引,
In [201]: df_sort.index.tolist()
Out[201]: [2, 4]
对于数值,
In [202]: df_sort['num'].tolist()
Out[202]: [4, 2]
对于上述解决方案,df 是关键。
In [197]: df
Out[197]:
num
0 1
1 6
2 4
3 5
4 2
除了不能完全回答问题之外,其他在这里讨论的算法的额外缺点是它们必须对整个列表进行排序。这导致了复杂度为 ~N log(N)。
然而,可以通过以下方法在 ~N 的时间内获得相同结果。该方法将数据框分成两个子集,一个小于所需值,另一个大于所需值。较小数据帧中的最大值是下限相邻值,而较大数据帧中的最小值是上限相邻值。
这给出以下代码片段:
def find_neighbours(value, df, colname):
exactmatch = df[df[colname] == value]
if not exactmatch.empty:
return exactmatch.index
else:
lowerneighbour_ind = df[df[colname] < value][colname].idxmax()
upperneighbour_ind = df[df[colname] > value][colname].idxmin()
return [lowerneighbour_ind, upperneighbour_ind]
这种方法类似于使用 pandas中的partition,在处理大型数据集并且遇到复杂性问题时非常有用。
比较这两种策略可以发现,对于大的N,分区策略确实更快。对于小的N,排序策略将更有效,因为它是在更低的级别上实现的。它还是一行代码,可能增加了代码的可读性。
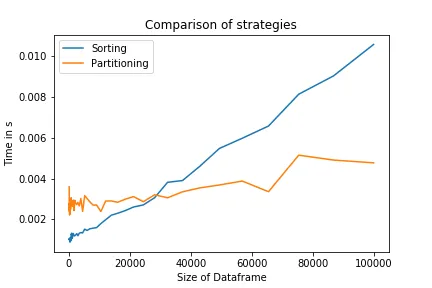
复制此图表的代码如下:
from matplotlib import pyplot as plt
import pandas
import numpy
import timeit
value=3
sizes=numpy.logspace(2, 5, num=50, dtype=int)
sort_results, partition_results=[],[]
for size in sizes:
df=pandas.DataFrame({"num":100*numpy.random.random(size)})
sort_results.append(timeit.Timer("df.iloc[(df['num']-value).abs().argsort()[:2]].index",
globals={'find_neighbours':find_neighbours, 'df':df,'value':value}).autorange())
partition_results.append(timeit.Timer('find_neighbours(df,value)',
globals={'find_neighbours':find_neighbours, 'df':df,'value':value}).autorange())
sort_time=[time/amount for amount,time in sort_results]
partition_time=[time/amount for amount,time in partition_results]
plt.plot(sizes, sort_time)
plt.plot(sizes, partition_time)
plt.legend(['Sorting','Partitioning'])
plt.title('Comparison of strategies')
plt.xlabel('Size of Dataframe')
plt.ylabel('Time in s')
plt.savefig('speed_comparison.png')
lower...是小于value的最大值,而upper...是大于lower的最小值。我不明白还有什么其他值可以在它们之间?或者你指的是其他的东西? - Ivo Merchiersvalue); 因为我对错误大约90%确定,而不是100%,所以我还有点犹豫是否编辑和修复答案。 - 9769953df 的大小。我添加了一个图表和一些代码来说明这种行为。 - Ivo Merchiers我建议除了John Galt的答案之外,还要使用iloc,因为这将即使在未排序的整数索引下也能正常工作,因为.ix首先查看索引标签。
df.iloc[(df['num']-input).abs().argsort()[:2]]
ix已被弃用:http://pandas-docs.github.io/pandas-docs-travis/whatsnew.html#deprecate-ix - ecoeidx = bisect_left(df['num'].values, 3)
假设数据框df的列col已排序。
val在该列中,bisect_left将返回列表中值的精确索引,bisect_right将返回下一个位置的索引。bisect_left和bisect_right将返回相同的索引:将该值插入到保持列表排序的位置。因此,为了回答这个问题,以下代码在找到val在col中的索引时起作用,否则会返回最接近的值的索引。即使列表中的值不唯一,此解决方案也可以工作。
from bisect import bisect_left, bisect_right
def get_closests(df, col, val):
lower_idx = bisect_left(df[col].values, val)
higher_idx = bisect_right(df[col].values, val)
if higher_idx == lower_idx: #val is not in the list
return lower_idx - 1, lower_idx
else: #val is in the list
return lower_idx
import pandas as pd
source = pd.Series([1,6,4,5,2])
target = 3
def find_closest_values(target, source, k_matches=1):
k_above = source[source >= target].nsmallest(k_matches+1)
k_below = source[source < target].nlargest(k_matches)
k_all = pd.concat([k_below, k_above]).sort_values()
return k_all
find_closest_values(target, source, k_matches=1)
输出:
4 2
2 4
dtype: int64
numpy.searchsorted。如果你的搜索列没有排序,你可以创建一个已排序的DataFrame,并使用pandas.argsort记住它们之间的映射。(如果你计划多次查找最接近的值,这比上述方法更好。)一旦排序完成,可以像这样查找输入的最接近值:indLeft = np.searchsorted(df['column'], input, side='left')
indRight = np.searchsorted(df['column'], input, side='right')
valLeft = df['column'][indLeft]
valRight = df['column'][indRight]
def closest(df, col, val, direction):
n = len(df[df[col] <= val])
if(direction < 0):
n -= 1
if(n < 0 or n >= len(df)):
print('err - value outside range')
return None
return df.ix[n, col]
df = pd.DataFrame(pd.Series(range(0,10,2)), columns=['num'])
for find in range(-1, 2):
lc = closest(df, 'num', find, -1)
hc = closest(df, 'num', find, 1)
print('Closest to {} is {}, lower and {}, higher.'.format(find, lc, hc))
df: num
0 0
1 2
2 4
3 6
4 8
err - value outside range
Closest to -1 is None, lower and 0, higher.
Closest to 0 is 0, lower and 2, higher.
Closest to 1 is 0, lower and 2, higher.
如果您需要在“num”列中找到最接近obj_num的值,并且在有多个选择的情况下,可以根据其他列(例如第二列'num2')的值选择最佳出现次数。
为此,我建议创建一个新列'num_diff',然后使用sort_values。例如:我们想要选择在“num”列中最接近3的值,并且在有许多出现次数的情况下,在“num2”列上选择最小值。代码如下:
import pandas as pd
obj_num = 3
df = pd.DataFrame({
'num': [0, 1, 3, 3, 3, 4],
'num2': [0, 0, 0, -1, 1, 0]
})
df_copy = df.loc[:, ['num', 'num2']].copy()
df_copy['num_diff'] = (df['num']-obj_num).abs()
df_copy.sort_values(
by=['num_diff', 'num2'],
axis=0,
inplace=True
)
obj_num_idx = df_copy.index[0]
print(f'Objective row: \n{df.loc[obj_num_idx, :]}')
def colosest_row(df, obj):
'''
Sort df using specific columns given as obj keys.
If a key has None value:
sort column in ascending order.
If a key has a float value:
sort column from closest to farest value from obj[key] value.
Arguments
---------
df: pd.DataFrame
contains at least obj keys in its columns.
obj: dict
dict of objective columns.
Return
------
index of closest row to obj
'''
df_copy = df.loc[:, [*obj]].copy()
special_cols = []
obj_cols = []
for key in obj:
if obj[key] is None:
obj_cols.append(key)
else:
special_cols.append(key)
obj_cols.append(f'{key}_diff')
for key in special_cols:
df_copy[f'{key}_diff'] = (df[key]-obj[key]).abs()
df_copy.sort_values(
by=obj_cols,
axis=0,
ascending=True,
inplace=True
)
return df_copy.index[0]
obj_num_idx = colosest_row(
df=df,
obj={
"num": obj_num,
"num2": None # Sort using also 'num2'
}
)
这里有很多答案,其中许多都非常好。没有一个被接受,@Zero的答案目前评分最高。另一个答案指出当索引未排序时它不起作用,但他/她推荐了一个看起来已经过时的解决方案。
我发现我可以使用numpy版本的argsort()在以下方式中对值本身进行排序,即使索引未排序也可以:
df.iloc[(df['num']-input).abs()..values.argsort()[:2]]
请参考Zero的回答以获取上下文。