最近,我注意到我的新工作站出现了一种无法解释的行为。通过对这个问题进行一些研究,可能存在一个INTEL Haswell architecture和当前的Skylake Generation中的潜在漏洞。
在谈论可能的漏洞之前,让我先给你介绍一下使用的硬件、程序代码和问题本身。
工作站硬件规格
- INTEL Xeon E5-2680 V3 2500MHz 30M Cache 12Core
- Supermicro SC745 BTQ -R1K28B-SQ
- 4 x 32GB ECC Registered DDR4-2133内存
- INTEL SSD 730系列480 GB
- NVIDIA Tesla C2075
- NVIDIA TITAN
涉及的操作系统和程序代码
我目前正在运行Ubuntu 15.04 64位桌面版本,最新的更新和内核组件已安装。除了使用这台计算机开发CUDA内核和其他东西之外,我最近测试了一个纯C程序。
该程序在相当大的数据输入集上执行一种修改后的ART。因此,代码执行一些FFT并消耗相当多的时间来完成计算。由于这是无法发布的正在进行的研究,因此我目前无法发布/链接到任何源代码。如果您不熟悉ART,请简单解释一下它的作用。ART是一种技术,用于重建从计算机断层扫描仪接收到的数据,以获得可见的诊断图像。因此,我们的代码版本重构了大小为2048x2048x512的数据集。到目前为止,还没有涉及任何特殊或高级的科学技术。经过几个小时的调试和修复错误,该代码已在参考结果上进行了测试,并且我们可以确认代码按照预期工作。代码唯一使用的库是标准math.h。没有特殊的编译参数,也没有可能带来额外问题的其他库。
观察问题
该代码使用一种技术来最小化重建数据所需的投影,实现了ART。因此,让我们假设我们可以重建涉及25个投影的数据切片。该代码在12个核心上以完全相同的输入数据启动。请注意,该实现不是基于多线程的,目前启动了12个程序实例。我知道这不是最好的方法,强烈建议涉及适当的线程管理,这已经列在改进列表中 :)
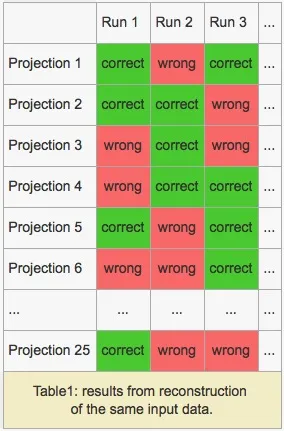
因此,当我们运行至少两个程序实例(每个实例处理一个单独的数据切片)时,结果中有一些投影以随机方式出错。为了让您了解结果,请参见Table1。请注意,输入数据始终相同。
仅运行涉及一个CPU核心的代码实例时,所有结果都是正确的。即使进行一些涉及一个CPU核心的运行,结果仍然正确。只有涉及两个或更多核心才会生成如表1所示的结果模式。
问题的识别
好的,我们花了相当长时间来了解实际上出了什么问题。因此,我们检查了整个代码,大多数问题都始于小的实现错误。但是,我们不能证明不存在错误,也不能保证不存在错误。为了验证我们的代码,我们使用了两台不同的机器:
- (Machine1) Intel Core i5 四核(2009 年底型号)
- (Machine2) 在 Intel XEON 6 核 SandyBridge CPU 上运行的虚拟机
令人惊讶的是,无论是 Machine1 还是 Machine2,都始终产生正确的结果。即使使用所有 CPU 核心,结果仍然正确。在每台机器上编译代码时,没有使用优化选项或任何特定的编译器设置。因此,通过阅读新闻,我们得出以下结论:
- 技术新闻网站Ars Technika - Skylake处理器在复杂工作负载下出现冻结问题
- PcWorld - 如何测试您的PC是否存在Skylake漏洞
- Intel社区 - 冻结Skylake处理器的简单指南
看起来Prime95和Mersenne Community的人似乎是第一个发现并识别这个nasty bug的人。参考帖子和新闻支持怀疑,该问题仅存在于重负载情况下。根据我的观察,我可以确认这种行为。
问题
- 您/社区是否在Haswell CPU和Skylake CPU上观察到了这个问题?
- 由于gcc默认进行AVX(2)优化(只要可能),关闭此优化会有所帮助吗?
- 我该如何编译我的代码并确保关闭可能受此漏洞影响的任何优化?到目前为止,我只读到过在Haswell / Skylake架构中使用AVX2命令集会有问题。
解决方案?
好的,我可以关闭所有AVX2优化。但这会减慢我的代码速度。英特尔可能会发布一个BIOS更新给主板制造商,以修改英特尔CPU中的微码。由于它似乎是一个硬件错误,即使更新了CPU的微码,这也可能变得有趣。我认为这可能是一个有效的选择,因为英特尔CPU使用一些由微码控制的RISC到CISC转换机制。编辑:Techreport.com - Errata prompts Intel to disable TSX in Haswell, early Broadwell CPUs 将检查CPU中的微码版本。
编辑2:截至目前(2016年1月19日15:39 CET),Memtest86+ v4.20正在运行并测试内存。由于这似乎需要很长时间才能完成,我将在明天更新帖子并公布结果。
EDIT3: 截至目前为止(2016年1月21日09:35 CET),Memtest86+已经完成了两次运行并通过了。甚至没有一个内存错误。将CPU的微代码从revision=0x2d更新到revision=0x36。目前正在准备源代码在此发布。问题仍然存在错误结果。由于我不是相关代码的作者,我必须进行双重检查以避免发布我不被允许发布的代码。我也在使用和维护这个工作站。EDIT4: (2016年1月22日)(12:15 CET)这里是用于编译源代码的Makefile:
# VARIABLES ==================================================================
CC = gcc
CFLAGS = --std=c99 -Wall
#LDFLAGS = -lm -lgomp -fast -s -m64
LDFLAGS = -lm
OBJ = ArtReconstruction2Min.o
# RULES AND DEPENDENCIES ====================================================
# linking all object files
all: $(OBJ)
$(CC) -o ART2Min $(OBJ) $(LDFLAGS)
# every o-file depends on the corresonding c-file, -g Option bedeutet Debugging Informationene setzen
%.o: %.c
$(CC) -c -g $< $(CFLAGS)
# MAKE CLEAN =================================================================
clean:
rm -f *.o
rm -f main
以及 gcc -v 的输出:
gcc -v
Using built-in specs.
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/usr/lib/gcc/x86_64-linux-gnu/4.9/lto-wrapper
Target: x86_64-linux-gnu
Configured with: ../src/configure -v --with-pkgversion='Ubuntu 4.9.2-10ubuntu13' --with-bugurl=file:///usr/share/doc/gcc-4.9/README.Bugs --enable-languages=c,c++,java,go,d,fortran,objc,obj-c++ --prefix=/usr --program-suffix=-4.9 --enable-shared --enable-linker-build-id --libexecdir=/usr/lib --without-included-gettext --enable-threads=posix --with-gxx-include-dir=/usr/include/c++/4.9 --libdir=/usr/lib --enable-nls --with-sysroot=/ --enable-clocale=gnu --enable-libstdcxx-debug --enable-libstdcxx-time=yes --enable-gnu-unique-object --disable-vtable-verify --enable-plugin --with-system-zlib --disable-browser-plugin --enable-java-awt=gtk --enable-gtk-cairo --with-java-home=/usr/lib/jvm/java-1.5.0-gcj-4.9-amd64/jre --enable-java-home --with-jvm-root-dir=/usr/lib/jvm/java-1.5.0-gcj-4.9-amd64 --with-jvm-jar-dir=/usr/lib/jvm-exports/java-1.5.0-gcj-4.9-amd64 --with-arch-directory=amd64 --with-ecj-jar=/usr/share/java/eclipse-ecj.jar --enable-objc-gc --enable-multiarch --disable-werror --with-arch-32=i686 --with-abi=m64 --with-multilib-list=m32,m64,mx32 --enable-multilib --with-tune=generic --enable-checking=release --build=x86_64-linux-gnu --host=x86_64-linux-gnu --target=x86_64-linux-gnu
Thread model: posix
gcc version 4.9.2 (Ubuntu 4.9.2-10ubuntu13)