我正在尝试使用AVX-AVX2指令集来测试连续数组上的流式处理性能。因此,我有以下示例,在其中进行基本的内存读取和存储。
#include <iostream>
#include <string.h>
#include <immintrin.h>
#include <chrono>
const uint64_t BENCHMARK_SIZE = 5000;
typedef struct alignas(32) data_t {
double a[BENCHMARK_SIZE];
double c[BENCHMARK_SIZE];
alignas(32) double b[BENCHMARK_SIZE];
}
data;
int main() {
data myData;
memset(&myData, 0, sizeof(data_t));
auto start = std::chrono::high_resolution_clock::now();
for (auto i = 0; i < std::micro::den; i++) {
for (uint64_t i = 0; i < BENCHMARK_SIZE; i += 1) {
myData.b[i] = myData.a[i] + 1;
}
}
auto end = std::chrono::high_resolution_clock::now();
std::cout << (end - start).count() / std::micro::den << " " << myData.b[1]
<< std::endl;
}
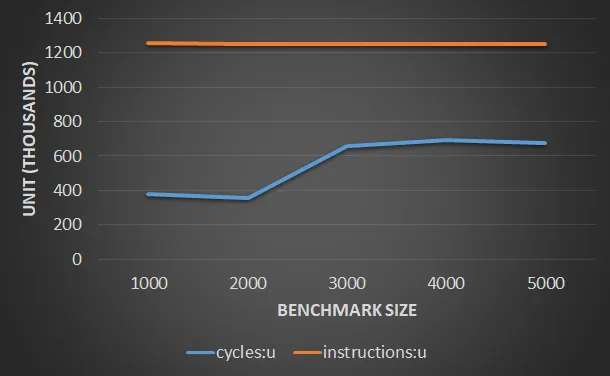
使用g++-4.9 -ggdb -march=core-avx2 -std=c++11 struct_of_arrays.cpp -O3 -o struct_of_arrays编译后,对于规模为4000的基准测试来说,我看到了相当不错的每周期指令性能和时间。然而,一旦我将基准测试规模增加到5000,我发现每周期指令性能显著下降,延迟也大幅跳升。我的问题是,尽管我可以看到性能下降似乎与L1缓存有关,但我无法解释为什么会这样突然。
更具体地说,如果我以4000和5000的基准测试规模运行perf,
| Event | Size=4000 | Size=5000 |
|-------------------------------------+-----------+-----------|
| Time | 245 ns | 950 ns |
| L1 load hit | 525881 | 527210 |
| L1 Load miss | 16689 | 21331 |
| L1D writebacks that access L2 cache | 1172328 | 623710387 |
| L1D Data line replacements | 1423213 | 624753092 |
我的问题是,鉴于Haswell应该能够在每个周期内提供2 * 32字节的读取和32字节的存储,为什么会发生这种影响?
编辑1
我意识到gcc通过巧妙地消除对myData.a的访问,因为它被设置为0。为了避免这种情况,我进行了另一个略有不同的基准测试,其中a被明确设置。
#include <iostream>
#include <string.h>
#include <immintrin.h>
#include <chrono>
const uint64_t BENCHMARK_SIZE = 4000;
typedef struct alignas(64) data_t {
double a[BENCHMARK_SIZE];
alignas(32) double c[BENCHMARK_SIZE];
alignas(32) double b[BENCHMARK_SIZE];
}
data;
int main() {
data myData;
memset(&myData, 0, sizeof(data_t));
std::cout << sizeof(data) << std::endl;
std::cout << sizeof(myData.a) << " cache lines " << sizeof(myData.a) / 64
<< std::endl;
for (uint64_t i = 0; i < BENCHMARK_SIZE; i += 1) {
myData.b[i] = 0;
myData.a[i] = 1;
myData.c[i] = 2;
}
auto start = std::chrono::high_resolution_clock::now();
for (auto i = 0; i < std::micro::den; i++) {
for (uint64_t i = 0; i < BENCHMARK_SIZE; i += 1) {
myData.b[i] = myData.a[i] + 1;
}
}
auto end = std::chrono::high_resolution_clock::now();
std::cout << (end - start).count() / std::micro::den << " " << myData.b[1]
<< std::endl;
}
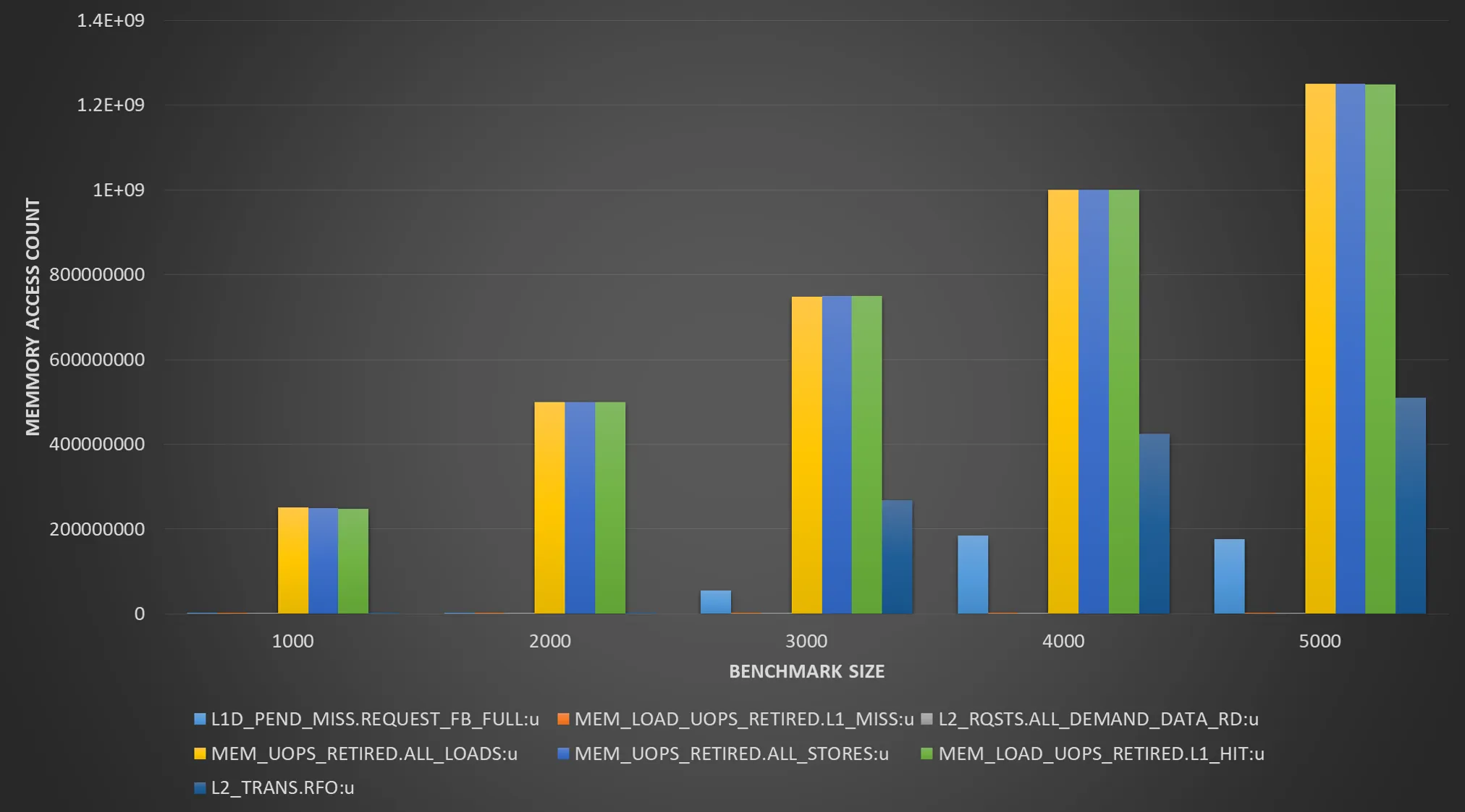
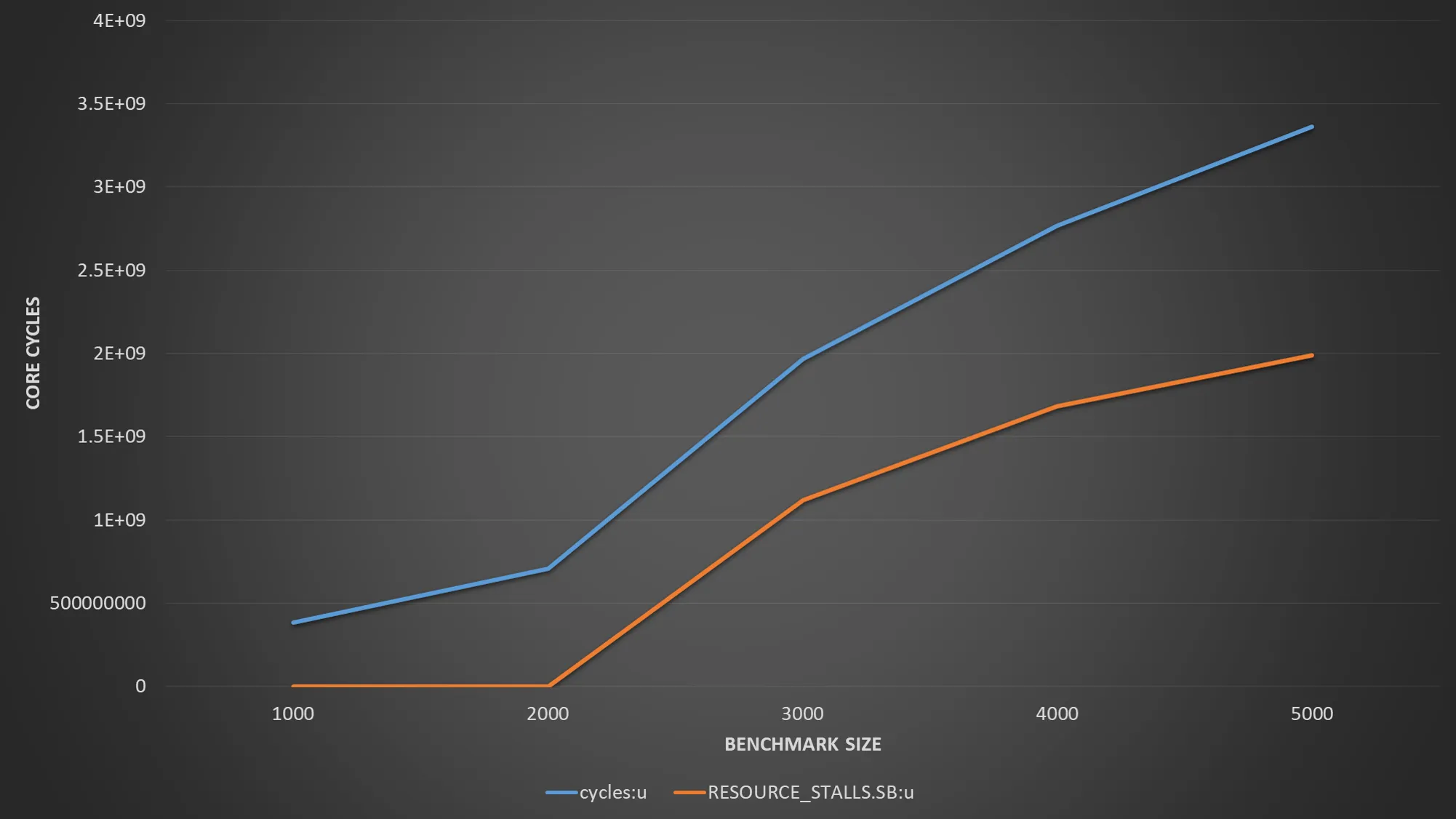
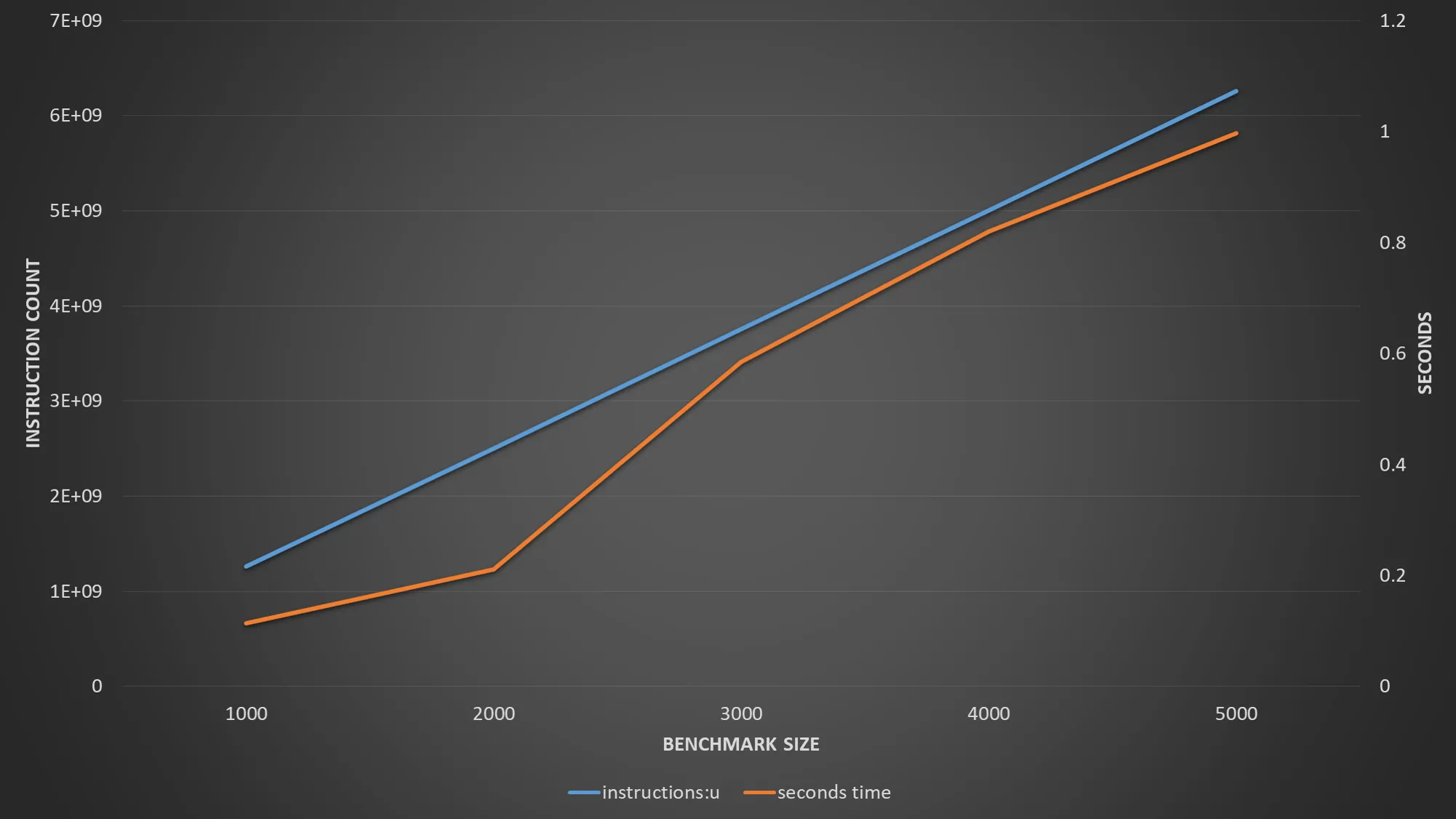
第二个例子将读取一个数组并写入另一个数组。对于不同的大小,它会产生以下性能输出:
| Event | Size=1000 | Size=2000 | Size=3000 | Size=4000 |
|----------------+-------------+-------------+-------------+---------------|
| Time | 86 ns | 166 ns | 734 ns | 931 ns |
| L1 load hit | 252,807,410 | 494,765,803 | 9,335,692 | 9,878,121 |
| L1 load miss | 24,931 | 585,891 | 370,834,983 | 495,678,895 |
| L2 load hit | 16,274 | 361,196 | 371,128,643 | 495,554,002 |
| L2 load miss | 9,589 | 11,586 | 18,240 | 40,147 |
| L1D wb acc. L2 | 9,121 | 771,073 | 374,957,848 | 500,066,160 |
| L1D repl. | 19,335 | 1,834,100 | 751,189,826 | 1,000,053,544 |
在答案中指出了一个相同的模式,随着数据集大小的增加,数据不再适合于L1缓存,而L2成为瓶颈。有趣的是,预取似乎没有起到作用,L1缺失显著增加。尽管我希望至少能看到50%的命中率,因为每个读取L1中缓存行的缓存行都将是第二次访问的命中(64字节缓存行32字节与每个迭代一起读取)。然而,一旦数据集溢出到L2,似乎L1命中率就会降至2%。考虑到数组实际上与L1缓存大小不重叠,这不应该是由于缓存冲突引起的。所以这部分对我来说仍然没有意义。