在 Xeon CPU(E5-2603)中,反向内存预取是否与正向内存预取一样快?
我想实现一个需要对数据进行正向循环和反向循环的算法。
由于每次迭代都需要上一次迭代的结果,我不能颠倒循环的顺序。
在 Xeon CPU(E5-2603)中,反向内存预取是否与正向内存预取一样快?
我想实现一个需要对数据进行正向循环和反向循环的算法。
由于每次迭代都需要上一次迭代的结果,我不能颠倒循环的顺序。
forfor1:9.9个周期。forfor2:15个周期。forback:35.8个周期。backback:40.3个周期。L1访问延迟对任何测量噪声都非常敏感。L2访问延迟平均应该为12个周期,但由于几个周期的噪声,我们仍可能得到L1命中的12个周期延迟。在第一次运行forfor时,大多数延迟为4个周期,这清楚地表明了L1命中。在第二次运行forfor时,大多数延迟为8或12个周期。我认为这些也可能是L1命中。在这两种情况下,都有一些L3命中和少量主存访问。对于forback和backback,我们可以看到大多数延迟是L3命中。这意味着L3预取器能够处理正向和反向遍历,但无法处理L1和L2预取器。
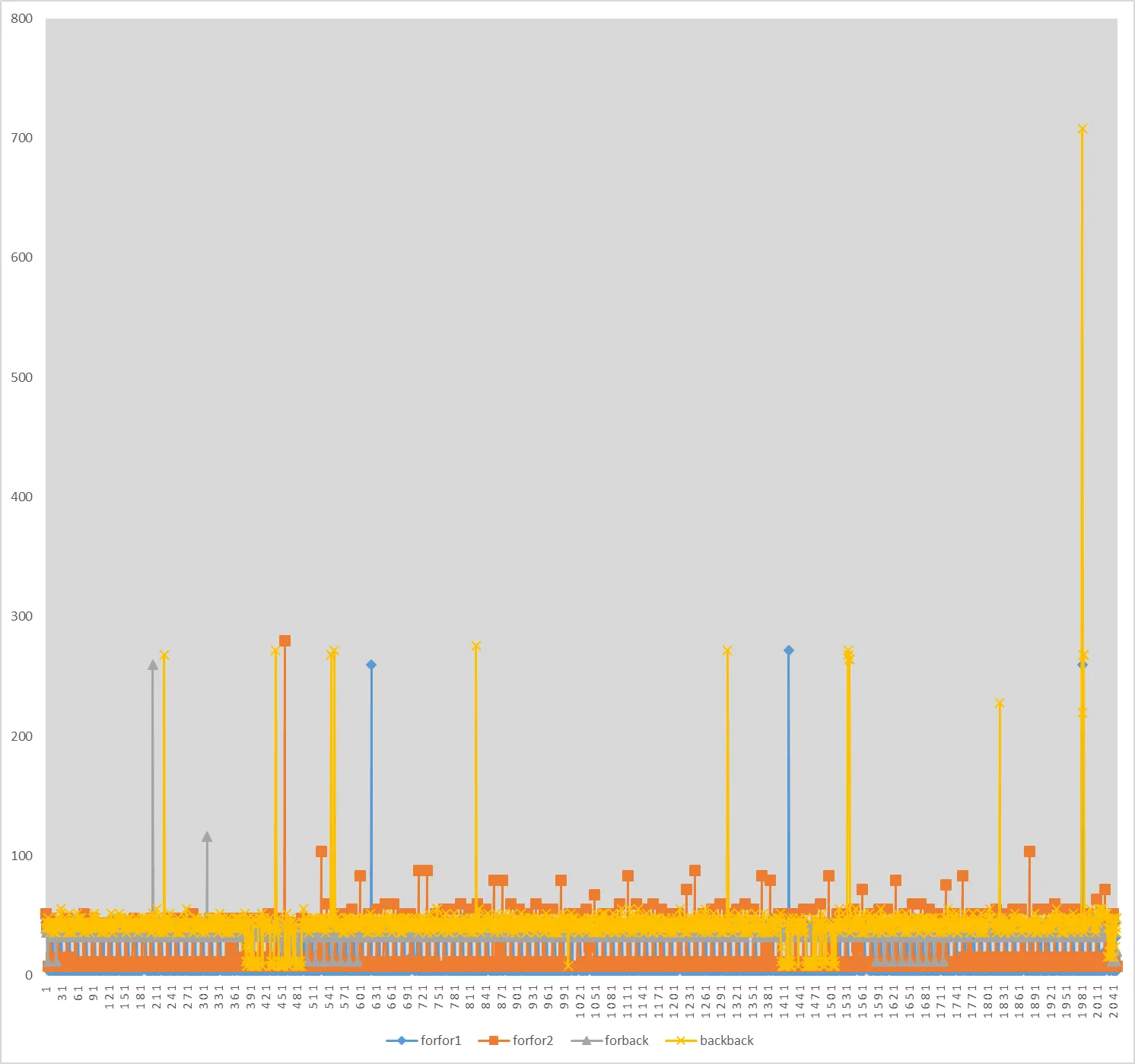
这是我用来进行测量的代码。
/* compile with gcc at optimization level -O3 */
/* set the minimum and maximum CPU frequency for all cores using cpupower to get meaningful results */
/* run using "sudo nice -n -20 ./a.out" to minimize possible context switches, or at least use "taskset -c 0 ./a.out" */
/* make sure all cache prefetchers are enabled */
/* preferrably disable HT */
/* this code is Intel-specific */
/* see the note at the end of the answer */
#include <stdint.h>
#include <x86intrin.h>
#include <stdio.h>
// 2048 iterations.
#define LINES_SIZE 64
#define ITERATIONS 2048 * LINES_SIZE
// Forward
#define START 0
#define END ITERATIONS
// Backward
//#define START ITERATIONS - LINES_SIZE
//#define END 0
#if START < END
#define INCREMENT i = i + LINES_SIZE
#define COMP <
#else
#define INCREMENT i = i - LINES_SIZE
#define COMP >=
#endif
int main()
{
int array[ ITERATIONS ];
int latency[ ITERATIONS/LINES_SIZE ];
uint64_t time1, time2, al, osl; /* initial values don't matter */
// Perhaps necessary to prevents UB?
for ( int i = 0; i < ITERATIONS; i = i + LINES_SIZE )
{
array[ i ] = i;
}
printf( "address = %p \n", &array[ 0 ] ); /* guaranteed to be aligned within a single cache line */
// Measure overhead.
_mm_mfence();
_mm_lfence(); /* mfence and lfence must be in this order + compiler barrier for rdtsc */
time1 = __rdtsc(); /* set timer */
_mm_lfence(); /* serialize rdtsc with respect to trailing instructions + compiler barrier for rdtsc */
/* no need for mfence because there are no stores in between */
_mm_lfence(); /* mfence and lfence must be in this order + compiler barrier for rdtsc */
time2 = __rdtsc();
_mm_lfence(); /* serialize rdtsc with respect to trailing instructions */
osl = time2 - time1;
// Forward or backward traversal.
for ( int i = START; i COMP END; INCREMENT )
{
_mm_mfence(); /* this properly orders both clflush and rdtsc */
_mm_lfence(); /* mfence and lfence must be in this order + compiler barrier for rdtsc */
time1 = __rdtsc(); /* set timer */
_mm_lfence(); /* serialize rdtsc with respect to trailing instructions + compiler barrier for rdtsc */
int temp = array[ i ]; /* access array[i] */
_mm_lfence(); /* mfence and lfence must be in this order + compiler barrier for rdtsc */
time2 = __rdtsc();
_mm_lfence(); /* serialize rdtsc with respect to trailing instructions */
al = time2 - time1;
printf( "array[ %i ] = %i \n", i, temp ); /* prevent the compiler from optimizing the load */
latency[i/64] = al - osl;
}
// Output measured latencies.
for ( int i = 0; i < ITERATIONS/LINES_SIZE; ++i )
{
printf( "%i \n", latency[i] );
}
return 0;
}
printf在每次迭代中被调用,污染了大量的L1和L2缓存。所以一定要使用>运算符。您也可以像this和this答案中建议的那样使用(void)*((volatile int*)array + i)而不是int tmp = array[i],这会更加可靠。lfence会阻止OoO执行隐藏L2命中延迟,而它通常可以做到这一点。 - Peter Cordeslfence! - BeeOnRope
-fprefetch-loop-arrays进行数据预取。此外,您还可以在代码中手动使用可移植的__builtin_prefetch进行预取。 - Hadi Brais