问题:获得接近0.64的r2。想要进一步提高我的结果。不知道这些结果的问题在哪里。已经去除了异常值,将字符串转换为数字,进行了归一化处理。想知道我的输出是否存在任何问题?如果我没有正确提出问题,请随时向我提问。这只是我在Stack Overflow上的开始。
y.value_counts()
3.3 215
3.0 185
2.7 154
3.7 134
2.3 96
4.0 54
2.0 31
1.7 21
1.3 20
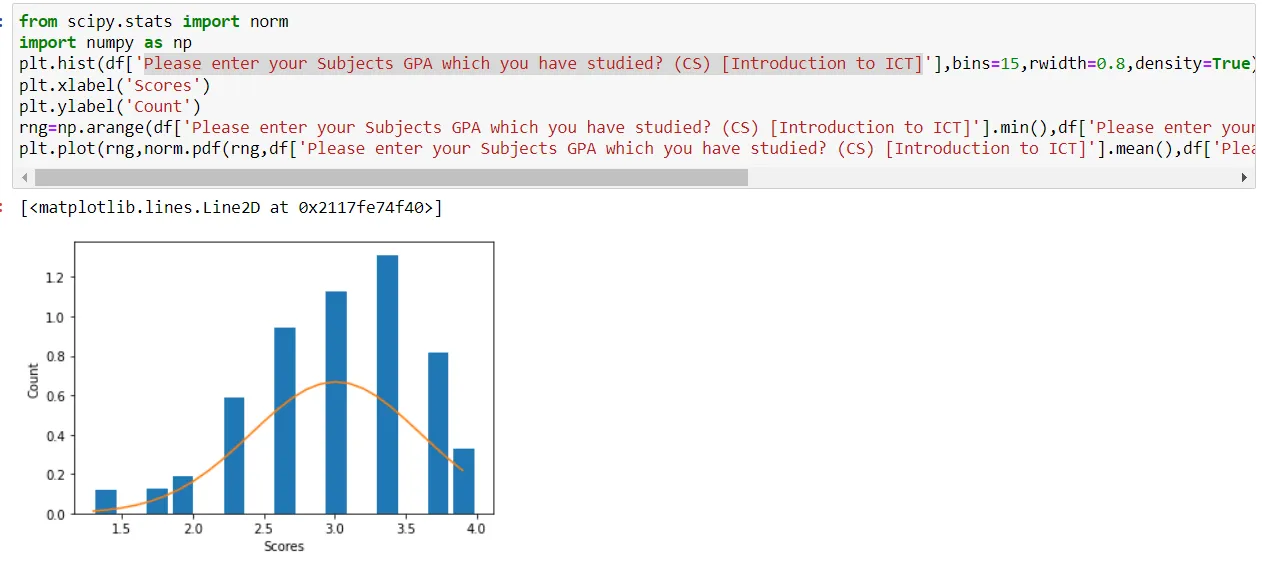
这是我的输出结果的直方图。我在回归方面不是专业人员,需要你的超级帮助。
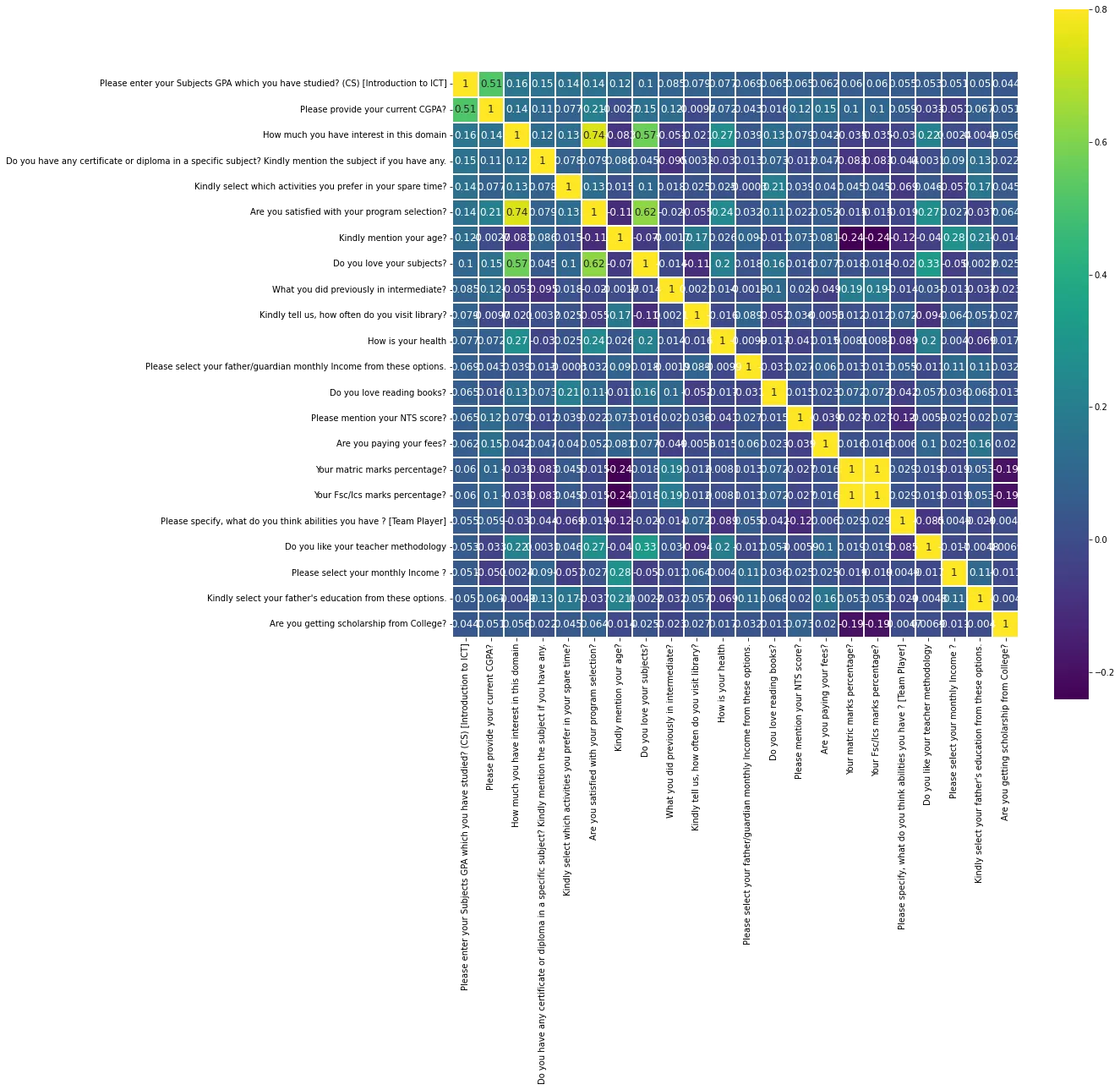
消除输入变量之间的共线性
import seaborn as sns
# data=z_scores(df)
data=df
correlation=data.corr()
k=22
cols=correlation.nlargest(k,'Please enter your Subjects GPA which you have studied? (CS) [Introduction to ICT]')['Please enter your Subjects GPA which you have studied? (CS) [Introduction to ICT]'].index
cm=np.corrcoef(data[cols].values.T)
f,ax=plt.subplots(figsize=(15,15))
sns.heatmap(cm,vmax=.8,linewidths=0.01,square=True,annot=True,cmap='viridis',
linecolor="white",xticklabels=cols.values,annot_kws={'size':12},yticklabels=cols.values)
cols=pd.DataFrame(cols)
cols=cols.set_axis(["Selected Features"], axis=1)
cols=cols[cols['Selected Features'] != 'Please enter your Subjects GPA which you have studied? (CS) [Introduction to ICT]']
cols=cols[cols['Selected Features'] != 'Your Fsc/Ics marks percentage?']
X=df[cols['Selected Features'].tolist()]
X
然后应用了随机森林回归器并得到以下结果
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=42)
from sklearn.ensemble import RandomForestRegressor
regressor = RandomForestRegressor(n_estimators = 10, random_state = 0)
model=regressor.fit(X_train, y_train)
y_pred = model.predict(X_test)
print("MAE Score: ", mean_absolute_error(y_test, y_pred))
print("MSE Score: ", mean_squared_error(y_test, y_pred))
print("RMSE Score: ", math.sqrt(mean_squared_error(y_test, y_pred)))
print("R2 score : %.2f" %r2_score(y_test,y_pred))
获取了这些结果。
MAE Score: 0.252967032967033
MSE Score: 0.13469450549450546
RMSE Score: 0.36700750059706605
R2 score : 0.64