单位:
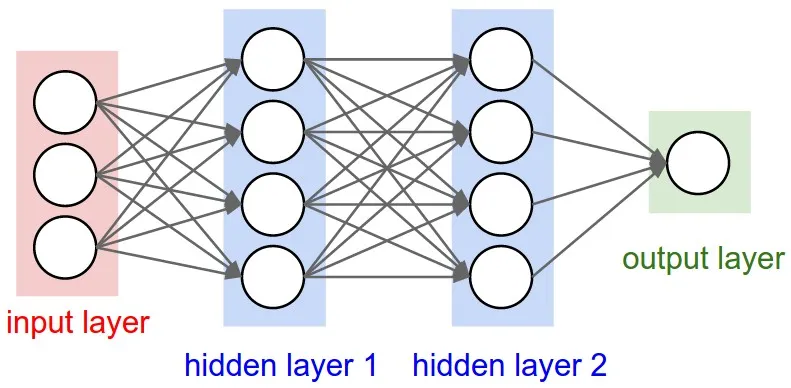
"神经元"、"细胞"或者说层内包含的任何东西的数量。
这是每个层的属性,与输出形状有关(我们稍后会看到)。在您的图片中,除了输入层之外,其他层概念上都不同,您有:
- 隐藏层1:4个单位(4个神经元)
- 隐藏层2:4个单位
- 最后一层:1个单位
形状
形状是模型配置的结果。形状是表示数组或张量在每个维度上具有多少元素的元组。
例如:形状 (30,4,10) 表示一个具有3个维度的数组或张量,在第一维中包含30个元素,在第二维中包含4个元素,在第三维中包含10个元素,总共有 30*4*10 = 1200 个元素或数字。
输入形状
在层之间流动的是张量。张量可以被视为具有形状的矩阵。
在Keras中,输入层本身不是一个层,而是一个张量。它是您发送到第一个隐藏层的起始张量。该张量必须与您的训练数据具有相同的形状。
例如:如果您有30个50x50像素的RGB图像(3个通道),则您的输入数据的形状为(30,50,50,3)。然后,您的输入层张量必须具有此形状(详见“Keras中的形状”部分)。
每种类型的层都需要具有特定数量维度的输入。
Dense层需要输入形状为(batch_size, input_size)或者(batch_size, optional,...,optional, input_size)- 2D卷积层需要输入形状为:
- 如果使用
channels_last: (batch_size, imageside1, imageside2, channels)
- 如果使用
channels_first: (batch_size, channels, imageside1, imageside2)
- 1D卷积和循环层使用
(batch_size, sequence_length, features)
现在,输入形状是您必须定义的唯一形状,因为您的模型无法知道它。只有您根据培训数据知道那个。
所有其他形状都是基于每个层的单元和特殊性自动计算的。
形状和单元之间的关系 - 输出形状
给定输入形状,所有其他形状都是层计算的结果。
每个层的“单元”将定义输出形状(即由该层生成的张量的形状,将成为下一层的输入)。每种类型的层都以特定方式工作。密集层的输出形状基于“单元”,卷积层的输出形状基于“过滤器”。但它总是基于某些层属性。(请参阅文档,了解每个层的输出)让我们展示一下“Dense”层会发生什么,这是你的图表中显示的类型。密集层的输出形状为(batch_size,units)。因此,确实,层的属性单元也定义了输出形状。
- 隐藏层1:4个单位,输出形状:
(batch_size,4)。
- 隐藏层2:4个单位,输出形状:
(batch_size,4)。
- 最后一层:1个单位,输出形状:
(batch_size,1)。
权重
权重将完全基于输入和输出形状自动计算。再次强调,每种类型的层都有其特定的工作方式。但是,权重将是一个矩阵,能够通过某些数学运算将输入形状转换为输出形状。
在稠密层中,权重乘以所有输入。它是一个矩阵,每个输入一列,每个单元一行,但这通常对基本工作不重要。在图像中,如果每个箭头上都有一个乘法数字,所有数字加在一起将形成权重矩阵。
Keras中的形状
之前,我举了一个例子,30张图片,大小为50x50像素,3个通道,具有输入形状(30,50,50,3)。
由于输入形状是您需要定义的唯一形状,因此Keras将在第一层中要求它。
但是,在此定义中,Keras忽略了批处理大小,您的模型应该能够处理任何批处理大小,因此只需定义其他维度。
input_shape = (50,50,3)
可选地,或者当某些模型需要时,您可以通过 batch_input_shape=(30,50,50,3) 或 batch_shape=(30,50,50,3) 传递包含批量大小的形状。这将限制您的训练可能性仅限于此唯一的批处理大小,因此只应在确实需要时使用。
无论您选择哪种方式,模型中的张量都将具有批处理维度。
因此,即使您使用了 input_shape=(50,50,3),当 keras 发送消息给您,或者当您打印模型摘要时,它将显示 (None,50,50,3)。
第一个维度是批处理大小,它为 None,因为它可以根据您提供的训练示例数量而变化。(如果您明确定义了批量大小,则定义的数字将出现在 None 的位置)
此外,在高级工作中,当您实际上直接操作张量(例如在 Lambda 层内部或损失函数中),批处理大小维度将存在。
- 因此,在定义输入形状时,忽略批量大小:
input_shape=(50,50,3)
- 当直接对张量进行操作时,形状将再次为
(30,50,50,3)
- 当Keras向您发送消息时,形状将是
(None,50,50,3)或(30,50,50,3),具体取决于它向您发送的消息类型。
维数
最后,什么是dim?
如果您的输入形状只有一个维度,则不需要将其作为元组给出,而是将input_dim作为标量数字给出。
因此,在您的模型中,如果您的输入层有3个元素,您可以使用以下任何一种:
input_shape=(3,) - 当您只有一个维度时,逗号是必需的input_dim = 3
但是,在直接处理张量时,dim 通常指张量的维数。例如,一个形状为(25,10909)的张量有2个维度。
在Keras中定义您的图像
Keras有两种方式,Sequential模型或函数API Model。我不喜欢使用顺序模型,因为以后你会忘记它,因为你会想要带有分支的模型。
PS:这里我忽略了其他方面,比如激活函数。
使用顺序模型:
from keras.models import Sequential
from keras.layers import *
model = Sequential()
model.add(Dense(units=4,input_shape=(3,)))
model.add(Dense(units=4))
model.add(Dense(units=1))
使用功能性 API 模型:
from keras.models import Model
from keras.layers import *
inpTensor = Input((3,))
hidden1Out = Dense(units=4)(inpTensor)
hidden2Out = Dense(units=4)(hidden1Out)
finalOut = Dense(units=1)(hidden2Out)
model = Model(inpTensor,finalOut)
张量的形状
在定义层时,请记住忽略批处理大小:
- inpTensor:
(None,3)
- hidden1Out:
(None,4)
- hidden2Out:
(None,4)
- finalOut:
(None,1)

input_shape=参数有一个问题:该参数的第一个值是指哪个维度?我看到一些类似于input_shape=(728, )的内容,所以在我看来第一个参数是指列(固定),第二个参数是指行(可以变化)。但是这与Python数组的行主序有什么关系呢? - Maxim.Kinput_shape(728,)与batch_input=(batch_size,728)相同。这意味着每个样本有728个值。 - Daniel Möllerdata_format ='channels_first'或data_format ='channels_last'。我建议始终使用channels last(Keras的默认设置)。它与所有其他层更兼容。 - Daniel Möller