我有一个如下所示的数据框
Re_MC,Fi_MC,Fin_id,Res_id,
1,2,3,4
,7,6,11
11,,31,32
,,35,38
df1 = pd.read_clipboard(sep=',')
我希望能够根据以下两个步骤来使用
fillna进行填充:a) 首先,仅比较
Re_MC和Fi_MC。如果这些列中的一个值缺失,则从另一列中复制它。b) 尽管执行了a步骤,如果
Re_MC或Fi_MC仍然为NA,则从Fin_id复制值到Fi_MC,并从Res_id复制值到Re_MC。因此,我尝试了以下两种方法: 方法1 - 能够起作用但不高效/优雅
df1['Re_MC'] = df1['Re_MC'].fillna(df1['Fi_MC'])
df1['Fi_MC'] = df1['Fi_MC'].fillna(df1['Re_MC'])
df1['Re_MC'] = df1['Re_MC'].fillna(df1['Res_id'])
df1['Fi_MC'] = df1['Fi_MC'].fillna(df1['Fin_id'])
方法2 - 这种方法不起作用并提供不正确的输出
df1['Re_MC'] = df1['Re_MC'].fillna(df1['Fi_MC']).fillna(df1['Res_id'])
df1['Fi_MC'] = df1['Fi_MC'].fillna(df1['Re_MC']).fillna(df1['Fin_id'])
有没有其他有效的方法按顺序填充fillna?意思是,我们首先进行“步骤a”,然后根据“步骤a”的结果,进行“步骤b”。
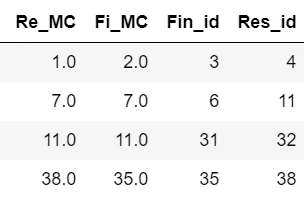
我希望我的输出如下所示。
更新的代码
df_new = (df_new
.fillna({'Re MC': df_new['Re Cust'],'Re MC': df_new['Re Cust_System']})
.fillna({'Fi MC' : df_new['Fi.Fi Customer'],'Final MC':df_new['Re.Fi Customer']})
.fillna({'Fi MC' : df_new['Re MC']})
.fillna({'Class Fi MC':df_new['Re MC']})
)