当您提到“高效”时,我认为您实际上想要的是 快速。
我将尝试简要讨论渐近效率。在这个背景下,我们将N称为输入大小,将K称为唯一值的数量。
我的解决方案是使用np.argsort()和一个专门针对NumPy输入进行优化的自定义 groupby_np()的组合:
import numpy as np
def groupby_np(arr, both=True):
n = len(arr)
extrema = np.nonzero(arr[:-1] != arr[1:])[0] + 1
if both:
last_i = 0
for i in extrema:
yield last_i, i
last_i = i
yield last_i, n
else:
yield 0
yield from extrema
yield n
def labeling_groupby_np(values, labels):
slicing = labels.argsort()
sorted_labels = labels[slicing]
sorted_values = values[slicing]
del slicing
result = {}
for i, j in groupby_np(sorted_labels, True):
result[sorted_labels[i]] = sorted_values[i:j]
return result
这个算法的时间复杂度为 O(N log N + K)。
其中 N log N 是排序所需的步骤,K 是最后一个循环所需的步骤。
有趣的是,无论是依赖于 N 还是依赖于 K 的步骤都很快,因为依赖于 N 的部分在低级别上执行,而依赖于 K 的部分是 O(1) 且也很快。
以下是类似于@theEpsilon回答的解决方案:
import numpy as np
def labeling_loop(values, labels):
labeled = {}
for x, l in zip(values, labels):
if l not in labeled:
labeled[l] = [x]
else:
labeled[l].append(x)
return {k: np.array(v) for k, v in labeled.items()}
使用两个循环,时间复杂度为 O(N + K)。我认为你很难避免第二个循环(如果这样做,速度会受到显著的惩罚)。至于第一个循环,在Python中执行本身就有很大的速度惩罚。
另一种可能性是使用np.unique()将主循环降低到更低的级别。但是,这会带来其他挑战,因为一旦提取了唯一值,没有有效的方法来提取信息以构建所需的数组,除非使用一些NumPy高级索引,这需要O(N)的时间复杂度。这些解决方案的总体复杂度为O(K * N),但由于NumPy高级索引是在较低的级别上完成的,因此这可以得到相对较快的解决方案,尽管其渐近复杂性不如替代方案。
可能的实现包括(类似于@AjayVerma和@AKX的答案):
import numpy as np
def labeling_unique_bool(values, labels):
return {l: values[l == labels] for l in np.unique(labels)}
import numpy as np
def labeling_unique_nonzero(values, labels):
return {l: values[np.nonzero(l == labels)] for l in np.unique(labels)}
此外,我们可以考虑进行预排序,通过避免使用NumPy高级索引来加快切片的速度。
然而,排序步骤可能比高级索引更耗费时间,在一般情况下,经过测试后发现这种方法更快。
import numpy as np
def labeling_unique_argsort(values, labels):
uniques, counts = np.unique(labels, return_counts=True)
sorted_values = values[labels.argsort()]
bound = 0
result = {}
for x, c in zip(uniques, counts):
result[x] = sorted_values[bound:bound + c]
bound += c
return result
另一种原则上很好(与我提出的方法相同),但实际上速度较慢的方法是使用排序和 itertools.groupby():
import itertools
from operator import itemgetter
def labeling_groupby(values, labels):
slicing = labels.argsort()
sorted_labels = labels[slicing]
sorted_values = values[slicing]
del slicing
result = {}
for x, g in itertools.groupby(zip(sorted_labels, sorted_values), itemgetter(0)):
result[x] = np.fromiter(map(itemgetter(1), g), dtype=sorted_values.dtype)
return result
最后,一个基于Pandas的方法,对于大型输入来说相当简洁和合理快速,但对于较小的输入表现不佳(类似于@Ehsan's answer):
def labeling_groupby_pd(values, labels):
df = pd.DataFrame({'values': values, 'labels': labels})
return df.groupby('labels').values.apply(lambda x: x.values).to_dict()
现在,光说不练假把式,让我们给快速和慢速加上一些数字,并为不同的输入大小生成一些图表。当 N 远大于52(英文字母的大小写数量)时,到达上限值的概率非常高。
以下是程序生成的输入:
def gen_input(n, p, labels=string.ascii_letters):
k = len(labels)
values = np.arange(n)
labels = np.array([string.ascii_letters[i] for i in np.random.randint(0, int(k * p), n)])
return values, labels
针对不同的p值,K的最大值发生了变化,p的取值为(1.0, 0.5, 0.1, 0.05),下面的图表按照此顺序显示p值。
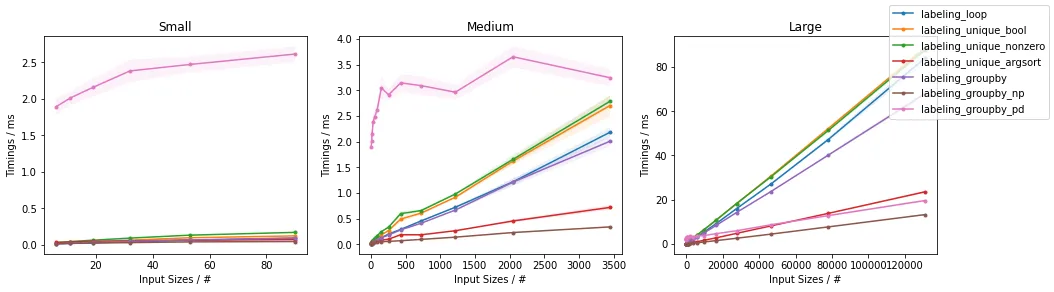
p=1.0(最多K = 52)
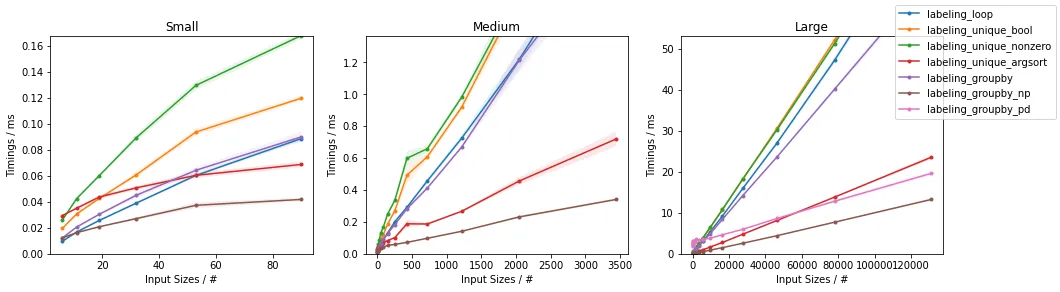
......并放大最快的部分
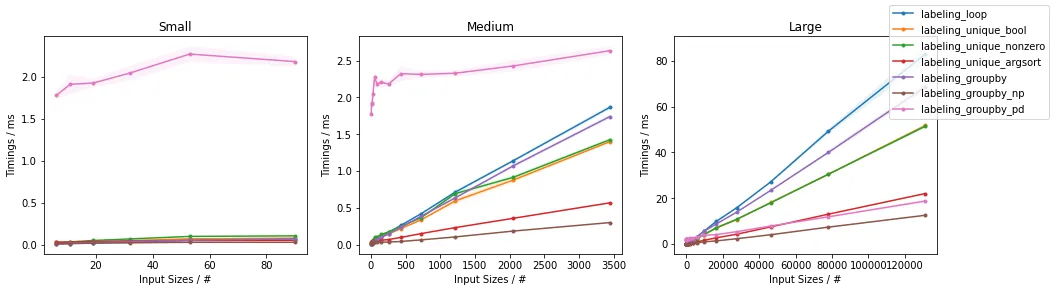
p=0.5(最多K = 26)
p=0.1(最多K = 5)
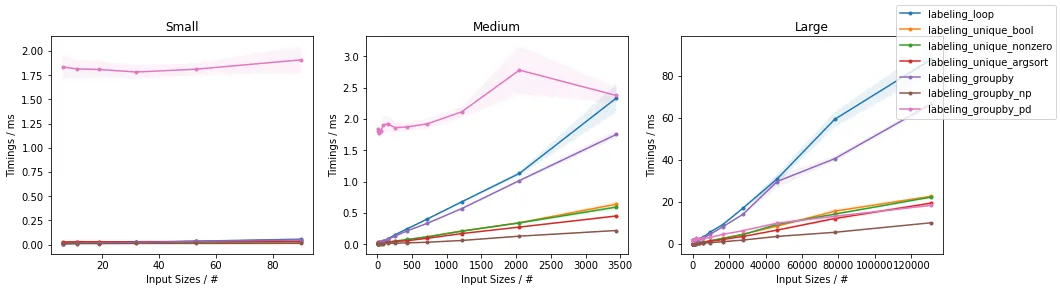
p=0.05(最多K = 2)
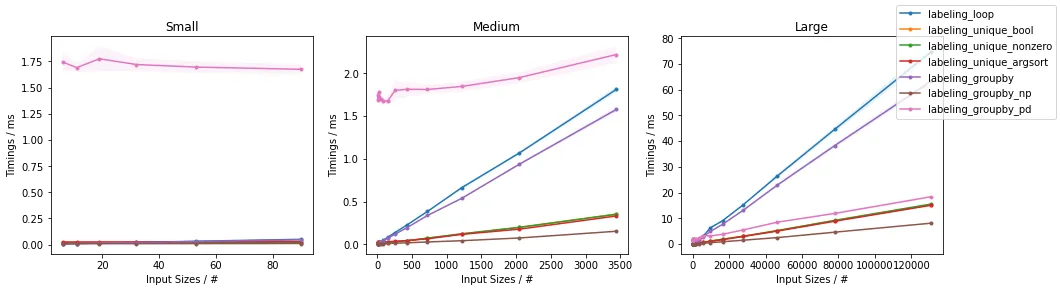
......并放大最快的部分
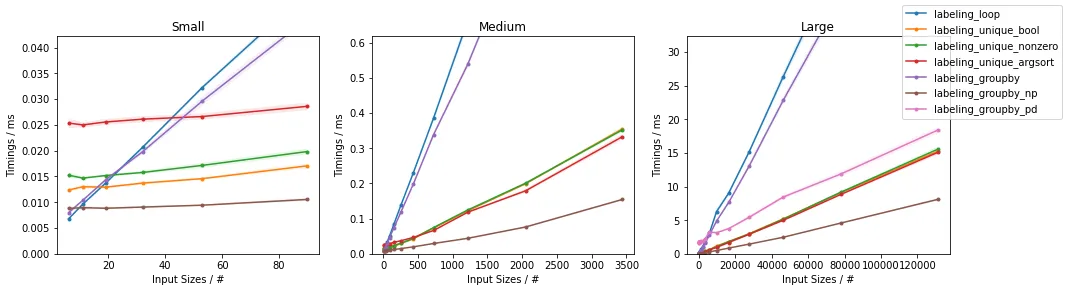
除了非常小的输入之外,可以看出所提出的方法在测试输入方面优于其他已经提出的方法。
(完整跑分结果在此处查看)。
也可以考虑将一些循环部分移动到Numba/Cython中,但我会留给感兴趣的读者去尝试。