我有一个类似下面的数据框。
索引 时间 周几 0 21:10:00 星期二 1 21:15:00 星期二 2 21:20:00 星期二 3 21:20:00 星期二 4 21:25:00 星期三 5 21:25:00 星期三 6 21:30:00 星期五 7 21:35:00 星期四 8 21:35:00 星期三 9 21:40:00 星期三 10 21:40:00 星期三 11 21:40:00 星期一
我想将每周的天数放入列中,并计算每个时间在每天出现的次数,我的目标是这样的:
索引 时间 周几 0 21:10:00 星期二 1 21:15:00 星期二 2 21:20:00 星期二 3 21:20:00 星期二 4 21:25:00 星期三 5 21:25:00 星期三 6 21:30:00 星期五 7 21:35:00 星期四 8 21:35:00 星期三 9 21:40:00 星期三 10 21:40:00 星期三 11 21:40:00 星期一
我想将每周的天数放入列中,并计算每个时间在每天出现的次数,我的目标是这样的:
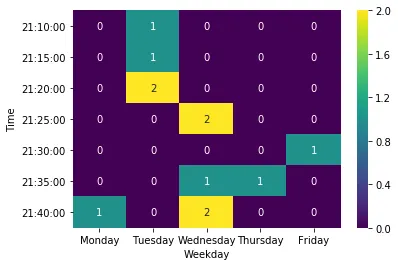
时间 星期一 星期二 星期三 星期四 星期五
21:10:00 0 1 0 0 0
21:15:00 0 1 0 0 0
21:20:00 0 2 0 0 0
21:25:00 0 0 2 0 0
21:30:00 0 0 0 0 1
21:35:00 0 0 1 1 0
21:40:00 1 0 2 0 0
这是因为我想在seaborn中创建一个热图,并且我读到我的数据必须按照某种方式进行透视/整理: https://dev59.com/6VoU5IYBdhLWcg3wIkaI#37790707
我知道如何计算每个Time值出现的频率,忽略星期几:
df['Time'].value_counts()
而且我一直在阅读http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.pivot.html,但我不知道如何将这两个想法结合起来。