我看到了很多关于x轴标记顺序的问题,但是还没有一个能解决我的问题。 我正在尝试制作一个密度图,显示每个给定分数内百分位数的人口分布,就像这样。
library(dplyr); library(ggplot2); library(ggtheme)
ggplot(KA,aes(x=percentile,group=kscore,color=kscore))+
xlab('Percentil')+ ylab('Frecuencia')+ theme_tufte()+ ggtitle("Prospectos")+
scale_color_brewer(palette = "Greens")+geom_density(size=3)
但是x轴的标记会像1,10,100,11,12,..,2,20,21,..,99这样排序,而不是我想要的1,2,3,..,100的顺序输出。
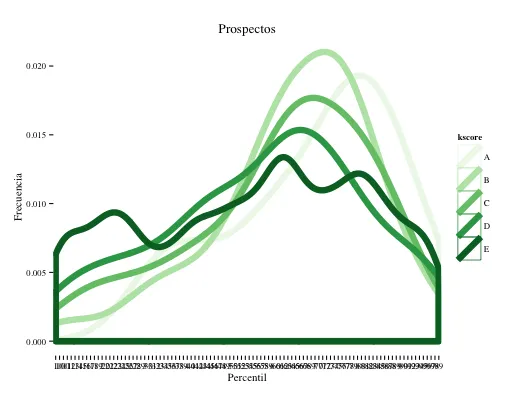 我担心这会影响整个图表而不仅仅是标签。
我担心这会影响整个图表而不仅仅是标签。
KA$percentile = as.numeric(as.character(KA$percentile))将其转换为数字型变量。 - Gregor Thomasdput(head(KA))可以帮助确认这一点。 - jeremycgdput(droplevels(head(KA)))会更好。 - Gregor Thomas