我有一个xlsx文件,其中的列有不同的颜色。
我想使用pandas在Python中仅读取此Excel文件中的白色列,但我不知道该如何做。
我能够将整个Excel读入数据框中,但是我错过了关于列颜色的信息,我不知道哪些列应该删除,哪些不应该删除。
(声明:我是要建议的库的作者之一)
使用StyleFrame(它包装了pandas),您可以将Excel文件读入数据框,而不会丢失样式数据。
考虑以下表格:
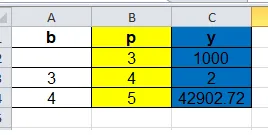
以及以下代码:
from styleframe import StyleFrame, utils
# from StyleFrame import StyleFrame, utils (if using version < 3.X)
sf = StyleFrame.read_excel('test.xlsx', read_style=True)
print(sf)
# b p y
# 0 nan 3 1000.0
# 1 3.0 4 2.0
# 2 4.0 5 42902.72396767148
sf = sf[[col for col in sf.columns
if col.style.fill.fgColor.rgb in ('FFFFFFFF', utils.colors.white)]]
# "white" can be represented as 'FFFFFFFF' or
# '00FFFFFF' (which is what utils.colors.white is set to)
print(sf)
# b
# 0 nan
# 1 3.0
# 2 4.0
openpyxl 库。
然后,您的脚本将按照以下步骤进行:
编辑:将 xlrd 更改为 openpyxl,因为 xlrd 不再得到积极维护。