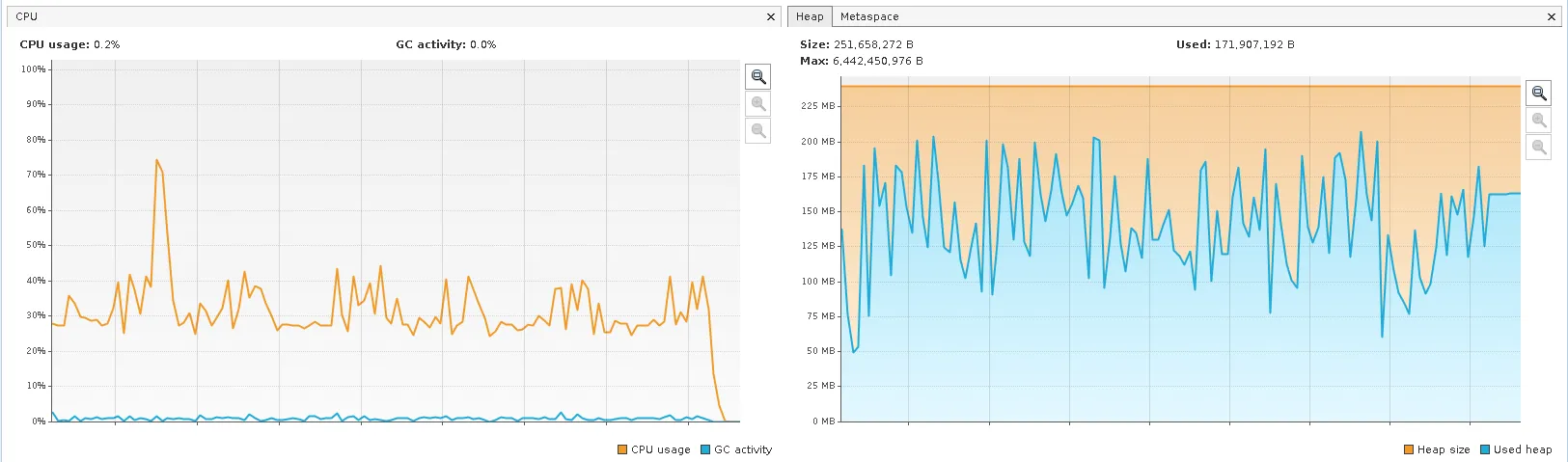
有人知道为什么使用Python3的functools.reduce()在连接多个PySpark数据框时会导致性能变差,而仅使用for循环迭代地连接相同的数据框却不会?具体来说,这会导致严重的减速,然后出现内存溢出错误:
def join_dataframes(list_of_join_columns, left_df, right_df):
return left_df.join(right_df, on=list_of_join_columns)
joined_df = functools.reduce(
functools.partial(join_dataframes, list_of_join_columns), list_of_dataframes,
)
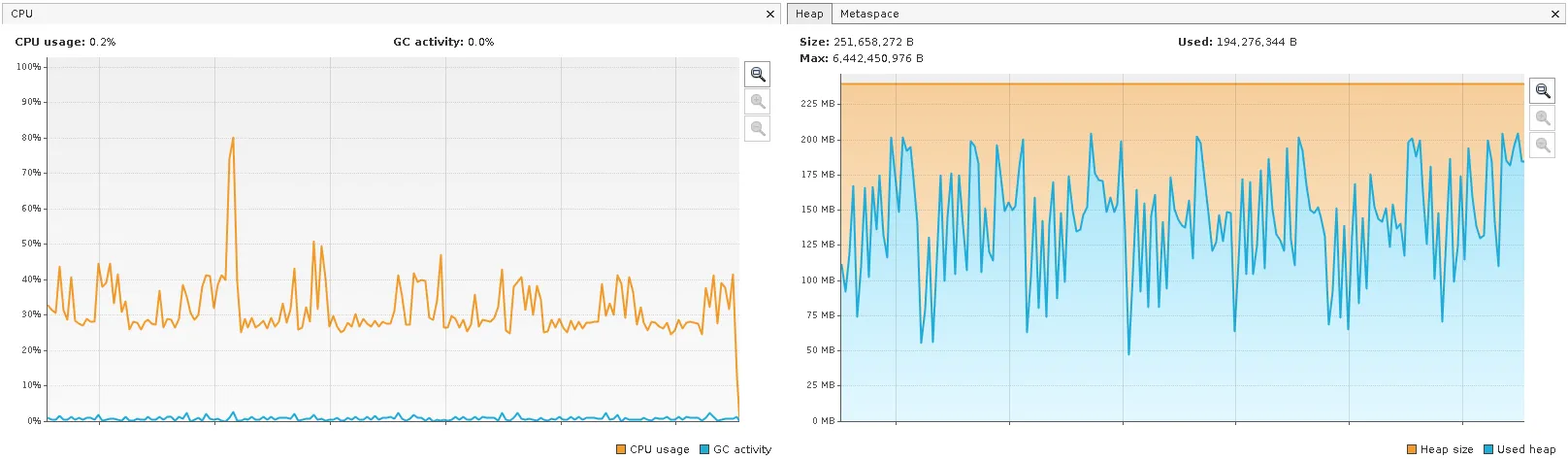
相比之下,这个没有:
joined_df = list_of_dataframes[0]
joined_df.cache()
for right_df in list_of_dataframes[1:]:
joined_df = joined_df.join(right_df, on=list_of_join_columns)
任何想法都将不胜感激。谢谢!
{kind=link}
{kind=link}
return reduce(lambda x, y: x.join(y, ["id"]), how="left", dfs)? - thentangler