df1 = pd.DataFrame({'a':['id1','id2','id3'],'b':['W','W','W'],'c1':[1,2,3]})
df2 = pd.DataFrame({'a':['id1','id2','id3'],'b':['W','W','W'],'c2':[4,5,6]})
df3 = pd.DataFrame({'a':['id1','id4','id5'],'b':['Q','Q','Q'],'c1':[7,8,9]})
我正在尝试将
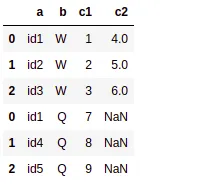
df1、df2和df3连接成一个数据框:a b c1 c2
id1 W 1 4
id2 W 2 5
id3 W 3 6
id1 Q 7 NA
id4 Q 8 NA
id5 Q 9 NA
我尝试了:
l = [d.set_index(['a','b']) for d in [df1,df2,df3]]
pd.concat(l, axis=1)
但输出结果与我的期望不符:
c1 c2 c1
a b
id1 W 1.0 4.0 NaN
id2 W 2.0 5.0 NaN
id3 W 3.0 6.0 NaN
id1 Q NaN NaN 7.0
id4 Q NaN NaN 8.0
id5 Q NaN NaN 9.0
{kind=link}