给定一个一维索引数组:
a = array([1, 0, 3])
我想将其作为一个二维数组进行one-hot编码:
b = array([[0,1,0,0], [1,0,0,0], [0,0,0,1]])
给定一个一维索引数组:
a = array([1, 0, 3])
我想将其作为一个二维数组进行one-hot编码:
b = array([[0,1,0,0], [1,0,0,0], [0,0,0,1]])
b,其列数为 a.max() + 1。i,将 a[i] 列设为 1。>>> a = np.array([1, 0, 3])
>>> b = np.zeros((a.size, a.max() + 1))
>>> b[np.arange(a.size), a] = 1
>>> b
array([[ 0., 1., 0., 0.],
[ 1., 0., 0., 0.],
[ 0., 0., 0., 1.]])
>>> values = [1, 0, 3]
>>> n_values = np.max(values) + 1
>>> np.eye(n_values)[values]
array([[ 0., 1., 0., 0.],
[ 1., 0., 0., 0.],
[ 0., 0., 0., 1.]])
np.max(values) + 1作为桶的数量可能并不理想。 桶的数量应该是一个参数,并且可以进行断言/检查以检查每个值是否在0(包括)和桶计数(不包括)之间。 - NightElfiknumpy文档的情况下,理解这个N维解决方案以及为什么它有效的简单方法是:在原始矩阵(values)中的每个位置上,我们有一个整数k,并且我们在该位置“放置”了1-hot向量eye(n)[k]。 这增加了一个维度,因为我们正在将向量“放置”到原始矩阵中标量的位置。 - avivr以下是我认为有用的内容:
def one_hot(a, num_classes):
return np.squeeze(np.eye(num_classes)[a.reshape(-1)])
在这里,num_classes表示你拥有的类别数量。如果你有一个形状为(10000,)的向量 a,此函数将把它转换为(10000,C)。请注意,a 是从零开始索引的,即 one_hot(np.array([0, 1]), 2) 将给出 [[1, 0], [0, 1]]。
我相信这正是你想要的。
PS:源自deeplearning.ai-序列模型
np.eye(num_classes)[a.reshape(-1)]可以得到大小为(向量a的大小)的独热编码数组。你所做的就是使用np.eye创建一个对角矩阵,其中每个类别索引为1,其余为0,然后使用a.reshape(-1)提供的索引生成与np.eye()中索引相对应的输出。我不明白为什么需要np.sqeeze,因为我们使用它只是为了删除单个维度,而我们永远不会有这样的维度,因为输出的维度始终为(a_flattened_size, num_classes)。 - Anu您还可以使用numpy的eye函数:
numpy.eye(类别数目)[包含标签的向量]
np.identity(num_classes)[indices]可能会更好。回答不错! - Olivernumpy.eye(num_class)[labels.reshape(-1)]。例如,如果标签维度为 (x,1),则它不会产生 (num_class, x, 1) 维度。 - Péter Szilvási您可以使用sklearn.preprocessing.LabelBinarizer:
示例:
import sklearn.preprocessing
a = [1,0,3]
label_binarizer = sklearn.preprocessing.LabelBinarizer()
label_binarizer.fit(range(max(a)+1))
b = label_binarizer.transform(a)
print('{0}'.format(b))
输出:
[[0 1 0 0]
[1 0 0 0]
[0 0 0 1]]
除了其他事情外,您可以初始化sklearn.preprocessing.LabelBinarizer(),以便transform的输出是稀疏的。
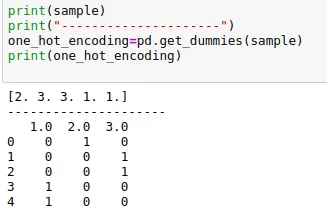
- Deepakimport pandas a = np.array([1,0,3]) one_hot_encode=pandas.get_dummies(a) print(one_hot_encode) 0 1 3 0 0 1 0 1 1 0 0 2 0 0 1 print(one_hot_encode[1]) 0 1 1 0 2 0 Name: 1, dtype: uint8 print(one_hot_encode[0]) 0 0 1 1 2 0 Name: 0, dtype: uint8 print(one_hot_encode[3]) 0 0 1 0 2 1 Name: 3, dtype: uint8`
这是一个将一维向量转换为二维one-hot数组的函数。
#!/usr/bin/env python
import numpy as np
def convertToOneHot(vector, num_classes=None):
"""
Converts an input 1-D vector of integers into an output
2-D array of one-hot vectors, where an i'th input value
of j will set a '1' in the i'th row, j'th column of the
output array.
Example:
v = np.array((1, 0, 4))
one_hot_v = convertToOneHot(v)
print one_hot_v
[[0 1 0 0 0]
[1 0 0 0 0]
[0 0 0 0 1]]
"""
assert isinstance(vector, np.ndarray)
assert len(vector) > 0
if num_classes is None:
num_classes = np.max(vector)+1
else:
assert num_classes > 0
assert num_classes >= np.max(vector)
result = np.zeros(shape=(len(vector), num_classes))
result[np.arange(len(vector)), vector] = 1
return result.astype(int)
>>> a = np.array([1, 0, 3])
>>> convertToOneHot(a)
array([[0, 1, 0, 0],
[1, 0, 0, 0],
[0, 0, 0, 1]])
>>> convertToOneHot(a, num_classes=10)
array([[0, 1, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0, 0, 0, 0]])
assert ___ 转换为 if not ___ raise Exception(<Reason>)。 - fnunnariimport numpy as np
np.eye(x.max()+1)[x]
为了进一步解释来自K3---rnc的优秀答案,这里提供一个更通用的版本:
def onehottify(x, n=None, dtype=float):
"""1-hot encode x with the max value n (computed from data if n is None)."""
x = np.asarray(x)
n = np.max(x) + 1 if n is None else n
return np.eye(n, dtype=dtype)[x]
def onehottify_only_1d(x, n=None, dtype=float):
x = np.asarray(x)
n = np.max(x) + 1 if n is None else n
b = np.zeros((len(x), n), dtype=dtype)
b[np.arange(len(x)), x] = 1
return b
>>> import numpy as np
>>> np.random.seed(42)
>>> a = np.random.randint(0, 9, size=(10_000,))
>>> a
array([6, 3, 7, ..., 5, 8, 6])
>>> %timeit onehottify(a, 10)
188 µs ± 5.03 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
>>> %timeit onehottify_only_1d(a, 10)
139 µs ± 2.78 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
{kind=link}