我很困惑为什么我的回归方程在数据集中超出了所有数据的范围。我有一种感觉,这个方程对于具有大波动的数据非常敏感,但我仍然感到困惑。任何帮助都将不胜感激,统计学肯定不是我的母语!
参考文献:这是一个地球化学热力学问题:我试图将Maier-Kelley方程拟合到一些实验数据上。Maier-Kelley方程描述了平衡常数(K),在这种情况下是白云石在水中溶解时随温度(T,以开尔文为单位)变化的方式。 log K = A + B.T + C/T + D.logT + E/T^2
简而言之(如果感兴趣,请参阅Hyeong和Capuano,2001),平衡常数(K)与Log_Ca_Mg(钙镁离子活性比)相同。
实验数据使用来自不同位置和不同深度的地下水数据(因此由FIELD和DepthID标识为我的随机变量)。
我包括了3个数据集。
(问题)数据集1:https://pastebin.com/fe2r2ebA
对于数据集2
对于数据集3
我已经绘制了“所有数据”,但对于回归分析,红线上方或绿线下方没有数据。 在任何温度下,仅包括在红线和绿线之间具有log_ca_mg值的点进行回归分析。
我有些迷茫,请帮忙理解此情况,谢谢。
参考文献:这是一个地球化学热力学问题:我试图将Maier-Kelley方程拟合到一些实验数据上。Maier-Kelley方程描述了平衡常数(K),在这种情况下是白云石在水中溶解时随温度(T,以开尔文为单位)变化的方式。 log K = A + B.T + C/T + D.logT + E/T^2
简而言之(如果感兴趣,请参阅Hyeong和Capuano,2001),平衡常数(K)与Log_Ca_Mg(钙镁离子活性比)相同。
实验数据使用来自不同位置和不同深度的地下水数据(因此由FIELD和DepthID标识为我的随机变量)。
我包括了3个数据集。
(问题)数据集1:https://pastebin.com/fe2r2ebA
(工作中)数据集2:https://pastebin.com/gFgaJ2c8
(工作中)数据集3:https://pastebin.com/X5USaaNA
使用以下代码,对数据集1进行操作:
> dat1 <- read.csv("PATH_TO_DATASET_1.txt", header = TRUE,sep="\t")
> fm1 <- lmer(Log_Ca_Mg ~ 1 + kelvin + I(kelvin^-1) + I(log10(kelvin)) + I(kelvin^-2) + (1|FIELD) +(1|DepthID),data=dat1)
Warning messages:
1: Some predictor variables are on very different scales: consider rescaling
2: In checkConv(attr(opt, "derivs"), opt$par, ctrl = control$checkConv, :
Model failed to converge with max|grad| = 0.0196619 (tol = 0.002, component 1)
3: Some predictor variables are on very different
> summary(fm1)
Linear mixed model fit by REML. t-tests use Satterthwaite's method ['lmerModLmerTest']
Formula: Log_Ca_Mg ~ 1 + kelvin + I(kelvin^-1) + I(log10(kelvin)) + I(kelvin^-2) + (1 | FIELD) + (1 | DepthID)
Data: dat1
REML criterion at convergence: -774.7
Scaled residuals:
Min 1Q Median 3Q Max
-3.5464 -0.4538 -0.0671 0.3736 6.4217
Random effects:
Groups Name Variance Std.Dev.
DepthID (Intercept) 0.01035 0.1017
FIELD (Intercept) 0.01081 0.1040
Residual 0.01905 0.1380
Number of obs: 1175, groups: DepthID, 675; FIELD, 410
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 3.368e+03 1.706e+03 4.582e-02 1.974 0.876
kelvin 4.615e-01 2.375e-01 4.600e-02 1.943 0.876
I(kelvin^-1) -1.975e+05 9.788e+04 4.591e-02 -2.018 0.875
I(log10(kelvin)) -1.205e+03 6.122e+02 4.582e-02 -1.968 0.876
I(kelvin^-2) 1.230e+07 5.933e+06 4.624e-02 2.073 0.873
Correlation of Fixed Effects:
(Intr) kelvin I(^-1) I(10()
kelvin 0.999
I(kelvn^-1) -1.000 -0.997
I(lg10(kl)) -1.000 -0.999 0.999
I(kelvn^-2) 0.998 0.994 -0.999 -0.997
fit warnings:
Some predictor variables are on very different scales: consider rescaling
convergence code: 0
Model failed to converge with max|grad| = 0.0196619 (tol = 0.002, component 1)
对于数据集2
> summary(fm2)
Linear mixed model fit by REML. t-tests use Satterthwaite's method ['lmerModLmerTest']
Formula: Log_Ca_Mg ~ 1 + kelvin + I(kelvin^-1) + I(log10(kelvin)) + I(kelvin^-2) + (1 | FIELD) + (1 | DepthID)
Data: dat2
REML criterion at convergence: -1073.8
Scaled residuals:
Min 1Q Median 3Q Max
-3.0816 -0.4772 -0.0581 0.3650 5.6209
Random effects:
Groups Name Variance Std.Dev.
DepthID (Intercept) 0.007368 0.08584
FIELD (Intercept) 0.014266 0.11944
Residual 0.023048 0.15182
Number of obs: 1906, groups: DepthID, 966; FIELD, 537
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) -9.366e+01 2.948e+03 1.283e-03 -0.032 0.999
kelvin -2.798e-02 4.371e-01 1.289e-03 -0.064 0.998
I(kelvin^-1) 2.623e+02 1.627e+05 1.285e-03 0.002 1.000
I(log10(kelvin)) 3.965e+01 1.067e+03 1.283e-03 0.037 0.999
I(kelvin^-2) 2.917e+05 9.476e+06 1.294e-03 0.031 0.999
Correlation of Fixed Effects:
(Intr) kelvin I(^-1) I(10()
kelvin 0.999
I(kelvn^-1) -0.999 -0.997
I(lg10(kl)) -1.000 -0.999 0.999
I(kelvn^-2) 0.998 0.994 -0.999 -0.997
fit warnings:
Some predictor variables are on very different scales: consider rescaling
convergence code: 0
Model failed to converge with max|grad| = 0.0196967 (tol = 0.002, component 1)
对于数据集3
> summary(fm2)
Linear mixed model fit by REML. t-tests use Satterthwaite's method ['lmerModLmerTest']
Formula: Log_Ca_Mg ~ 1 + kelvin + I(kelvin^-1) + I(log10(kelvin)) + I(kelvin^-2) + (1 | FIELD) + (1 | DepthID)
Data: dat3
REML criterion at convergence: -1590.1
Scaled residuals:
Min 1Q Median 3Q Max
-4.2546 -0.4987 -0.0379 0.4313 4.5490
Random effects:
Groups Name Variance Std.Dev.
DepthID (Intercept) 0.01311 0.1145
FIELD (Intercept) 0.01424 0.1193
Residual 0.03138 0.1771
Number of obs: 6674, groups: DepthID, 3422; FIELD, 1622
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 1.260e+03 1.835e+03 9.027e-02 0.687 0.871
kelvin 1.824e-01 2.783e-01 9.059e-02 0.655 0.874
I(kelvin^-1) -7.289e+04 9.961e+04 9.044e-02 -0.732 0.866
I(log10(kelvin)) -4.529e+02 6.658e+02 9.028e-02 -0.680 0.872
I(kelvin^-2) 4.499e+06 5.690e+06 9.104e-02 0.791 0.860
Correlation of Fixed Effects:
(Intr) kelvin I(^-1) I(10()
kelvin 0.999
I(kelvn^-1) -1.000 -0.997
I(lg10(kl)) -1.000 -0.999 0.999
I(kelvn^-2) 0.998 0.994 -0.999 -0.998
fit warnings:
Some predictor variables are on very different scales: consider rescaling
convergence code: 0
unable to evaluate scaled gradient
Model failed to converge: degenerate Hessian with 1 negative eigenvalues
我已经绘制了“所有数据”,但对于回归分析,红线上方或绿线下方没有数据。 在任何温度下,仅包括在红线和绿线之间具有log_ca_mg值的点进行回归分析。
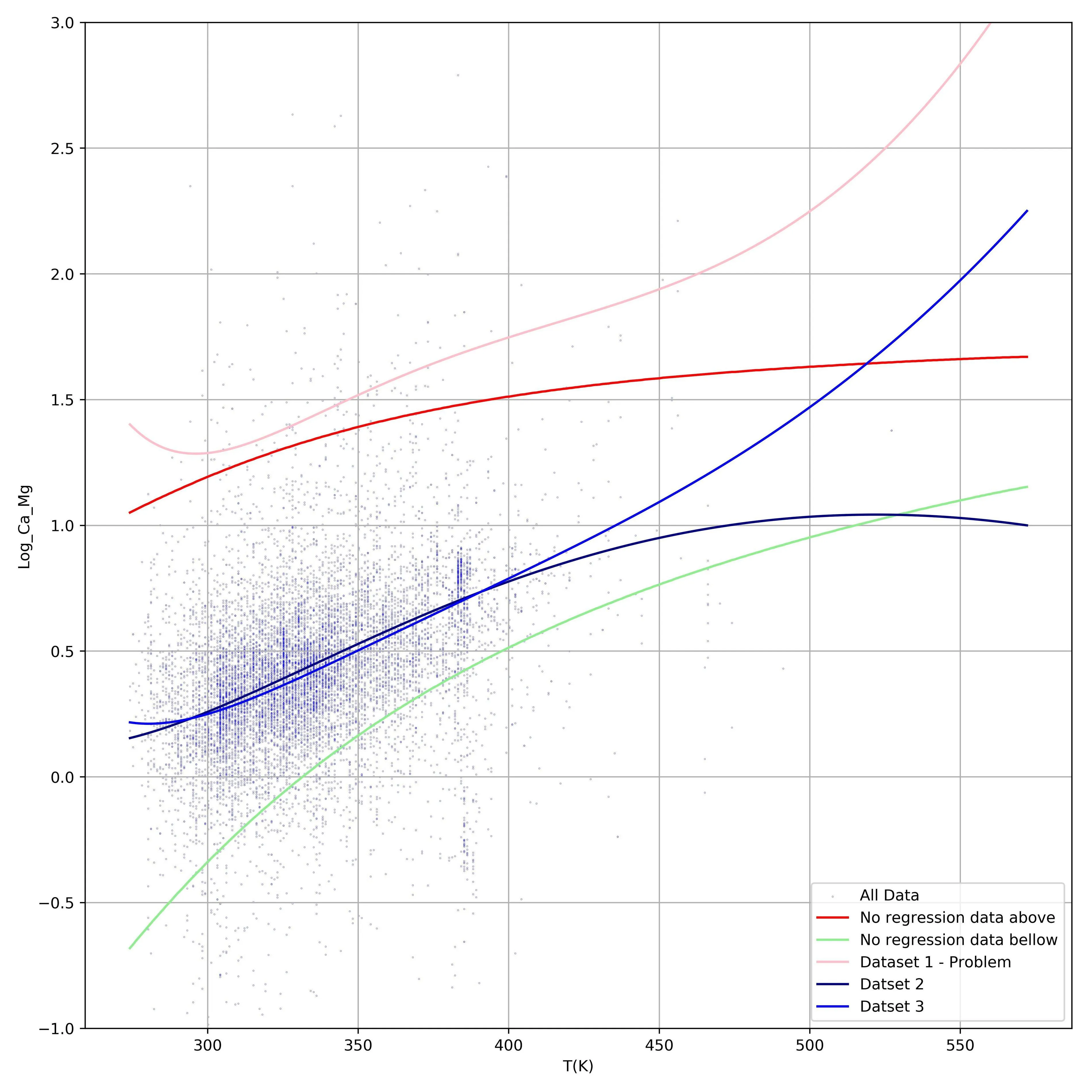
我有些迷茫,请帮忙理解此情况,谢谢。
Log_Ca_Mg ~ 1 + kelvin + I(100 * kelvin^-1) + I(log10(kelvin)) + I(1e4 * kelvin^-2) + (1 | FIELD) + (1 | DepthID)。 - Roland