我实在太好奇了,等不及回复就自己玩了一会儿:
我复制了文本سلام(英语中为“Hello”),并将其粘贴到Nodepad++中(在我的情况下使用UTF-8编码)。然后我切换到十六进制视图,得到了:

右侧的ASCII转储看起来有些类似于OP意外得到的内容。这让我相信
readData中的字节是用UTF-8编码的。因此,我取出了暴露的十六进制数字并编写了一个小样例代码:
testQPersian.cc:
#include <QtWidgets>
int main(int argc, char **argv)
{
QByteArray readData = "\xd8\xb3\xd9\x84\xd8\xa7\xd9\x85";
QString textLatin1 = QString::fromLatin1(readData);
QString textUtf8 = QString::fromUtf8(readData);
QApplication app(argc, argv);
QWidget qWin;
QGridLayout qGrid;
qGrid.addWidget(new QLabel("Latin-1:"), 0, 0);
qGrid.addWidget(new QLabel(textLatin1), 0, 1);
qGrid.addWidget(new QLabel("UTF-8:"), 1, 0);
qGrid.addWidget(new QLabel(textUtf8), 1, 1);
qWin.setLayout(&qGrid);
qWin.show();
return app.exec();
}
testQPersian.pro:
SOURCES = testQPersian.cc
QT += widgets
在Windows 10上使用cygwin编译并测试:
$ qmake-qt5 testQPersian.pro
$ make
$ ./testQPersian
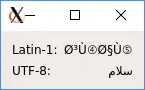
再次,使用Latin-1输出的结果与OP得到的结果以及Notepad++显示的结果有些相似。
使用UTF-8输出的结果提供了预期的文本(因为我提供了适当的UTF-8编码作为输入)。
也许,ASCII/Latin-1输出的差异有点令人困惑。存在多个字符字节编码,它们在下半部分(0 ... 127)共享ASCII,但在上半部分(128 ... 255)具有不同的字节含义。(查看ISO/IEC 8859以了解我的意思。这些已经作为本地化引入,然后Unicode成为本地化问题的最终解决方案。)
波斯字符肯定都具有超过127的Unicode代码点。(Unicode也共享前128个代码点的ASCII。)这些代码点在UTF-8中被编码为多个字节的序列,其中每个字节都具有MSB(最高有效位-位7)设置。因此,如果这些字节(意外地)使用任何ISO8859编码进行解释,则上半部分变得相关。因此,根据当前使用的ISO8859编码,这可能会产生不同的字形。
一些续篇:
OP发送了以下快照:
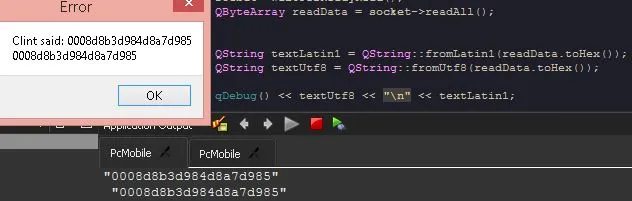
因此,看起来他得到的是
00 08 d8 b3 d9 84 d8 a7 d9 85
而不是
d8 b3 d9 84 d8 a7 d9 85
可能的解释:
服务器首先发送一个16位长度00 08,解释为大端16位整数:8,然后是8个以UTF-8编码的字节(看起来与上面所玩的一样)。
(据我所知,对于二进制网络协议来说,使用大端是很常见的,因为这可以防止发送方和接收方具有本地不同的字节顺序。)更多阅读请参见:htons(3)- Linux man页面
在i386上,主机字节顺序是最低有效字节优先,而Internet上使用的网络字节顺序是最高有效字节优先。
OP声称该协议使用DataOutput-writeUTF:
向输出流写入两个长度信息字节,后跟字符串s中每个字符的修改后的UTF-8表示形式。如果s为null,则抛出NullPointerException。字符串s中的每个字符都将转换为一个、两个或三个字节组,具体取决于字符的值。
因此,解码可能如下所示:
QByteArray readData("\x00\x08\xd8\xb3\xd9\x84\xd8\xa7\xd9\x85", 10);
unsigned length
= ((uint8_t)readData[0] << 8) + (uint8_t)readData[1];
QString text = QString::fromUtf8(dataRead.data() + 2, length);
从readData中提取前两个字节,并将它们组合成length(解码大端16位整数)。
余下的dataRead被转换为QString,提供之前提取的length。因此,跳过了readData的前两个长度字节。
QString DataAsString = QString::fromUtf8(readData)代替。codecForUtfText会查找字节序标记,如果找不到它会假定为Latin-1编码。 - Igor TandetnikreadData的值? - scopchanovQByteArray::toHex()将您的dataRead转换为十六进制转储,打印出来,并将结果添加到您的问题中(使用[编辑])。如果它与我在Notepad++中得到的相同,则您的编码是UTF-8。如果有什么不同,有人可能能够从数字中猜出它。 - Scheff's Cat