我有两个长度相等的数组(x1和x2),它们具有重叠的值范围。
我需要找到一个值q,使得l1-l2最小,并且
l1 = x1[np.where(x1 > q)].shape[0]
l2 = x2[np.where(x2 < q)].shape[0]
我希望您能提供较高性能的解决方案,因为数组可能很大。最好使用原生的numpy程序来解决。
我有两个长度相等的数组(x1和x2),它们具有重叠的值范围。
我需要找到一个值q,使得l1-l2最小,并且
l1 = x1[np.where(x1 > q)].shape[0]
l2 = x2[np.where(x2 < q)].shape[0]
可能有更聪明的查找值的方法,但您可以按以下方式进行全面搜索:
>>> x1 = np.random.rand(10)
>>> x2 = np.random.rand(10)
>>> x1.sort()
>>> x2.sort()
>>> x1
array([ 0.12568451, 0.30256769, 0.33478133, 0.41973331, 0.46493576,
0.52173197, 0.72289189, 0.72834444, 0.78662283, 0.78796277])
>>> x2
array([ 0.05513774, 0.21567893, 0.29953634, 0.37426842, 0.40000622,
0.54602497, 0.7225469 , 0.80116148, 0.82542633, 0.86736597])
如果q是x1中的一个项目,则我们可以计算出l1,如下:
>>> l1_x1 = len(x1) - np.arange(len(x1)) - 1
>>> l1_x1
array([9, 8, 7, 6, 5, 4, 3, 2, 1, 0])
对于相同的q,使用l2:
>>> l2_x1 = np.searchsorted(x1, x2)
>>> l2_x1
array([ 0, 1, 1, 3, 3, 6, 6, 10, 10, 10], dtype=int64)
当 q 在 x2 时,同样可以获取 l1 和 l2 的值:
>>> l2_x2 = np.arange(len(x2))
>>> l2_x2
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> l1_x2 = len(x1) - np.searchsorted(x1, x2, side='right')
>>> l1_x2
array([10, 9, 9, 7, 7, 4, 4, 0, 0, 0], dtype=int64)
然后你只需检查 l1 - l2 的最小值即可:
>>> np.concatenate((l1_x1 - l2_x1, l1_x2 - l2_x2))
array([ 9, 7, 6, 3, 2, -2, -3, -8, -9, -10, 10, 8, 7,
4, 3, -1, -2, -7, -8, -9], dtype=int64)
>>> q_idx = np.argmin(np.abs(np.concatenate((l1_x1 - l2_x1, l1_x2 - l2_x2))))
>>> q = x1[q_idx] if q_idx < len(x1) else x2[q_idx - len(x1)]
>>> q
0.54602497466094291
>>> x1[x1 > q].shape[0]
4L
>>> x2[x2 < q].shape[0]
5L
x1 = (50 - 10) * np.random.random(10000) + 10
x2 = (75 - 25) * np.random.random(10000) + 25
x1.sort()
x2.sort()
x2 = x2[::-1] # reverse the array
# The overlap point should fall where the difference is smallest
diff = np.abs(x1 - x2)
# get the index of where the minimum occurs
loc = np.where(diff == np.min(diff))
q1 = x1[loc] # 38.79087351
q2 = x2[loc] # 38.79110941
M4rtini的解决方案得出q = 38.7867527。
(x1 [i],x2 [i])都视为一个区间,则要找到将区间分成两组的值q,并尽可能平均地忽略与q重叠的区间。让我们先考虑简单的情况:from numpy import array
x1 = array([19, 32, 47, 13, 56, 1, 87, 48])
x2 = array([44, 38, 50, 39, 85, 26, 92, 64])
x1sort = np.sort(x1)
x2sort = np.sort(x2)[::-1]
diff = abs(x2sort - x1sort)
mindiff = diff.argmin()
print mindiff, x2sort[mindiff], x1sort[mindiff]
# 4 44 47
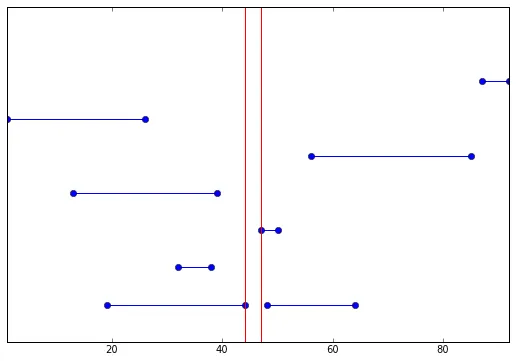
q值都是等效的,并产生最优结果。这里有一个稍微棘手一些的例子:x1 = array([12, 65, 46, 81, 71, 77, 37])
x2 = array([ 20, 85, 59, 122, 101, 87, 58])
x1sort = np.sort(x1)
x2sort = np.sort(x2)[::-1]
diff = abs(x2sort - x1sort)
mindiff = diff.argmin()
print mindiff, x2sort[mindiff], x1sort[mindiff], x1sort[mindiff-1]
# 59 71 65
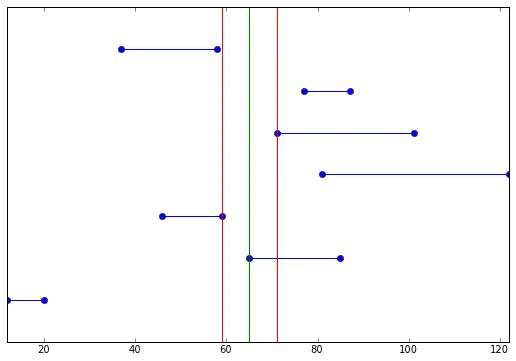
例如像这样:
import numpy as np
from scipy.optimize import fmin
def findQ(q, *x):
x1, x2 = x
l1 = x1[np.where(x1 > q)].shape[0]
l2 = x2[np.where(x2 < q)].shape[0]
return abs(l1-l2)
x1 = (50 - 10) * np.random.random(10000) + 10
x2 = (75 - 25) * np.random.random(10000) + 25
q0 = (min(x2) + max(x1))/2.0
q = fmin(findQ, q0, (x1,x2))
l1和l2的大小必须相同吗? - CT Zhu