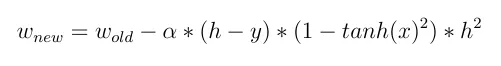我阅读了一些有关神经网络的内容,我理解单层神经网络的一般原理。我理解需要额外的层,但为什么要使用非线性激活函数?
这个问题之后还有一个问题:什么是反向传播中使用的激活函数的导数?
这个问题之后还有一个问题:什么是反向传播中使用的激活函数的导数?
激活函数的目的是为了在神经网络中引入非线性,
进而使你能够对响应变量(也称为目标变量,类别标签或分数)进行建模,该变量与其解释变量呈现非线性关系。
非线性意味着输出不能从输入的线性组合中重现(这与输出呈现直线的情况不同--这种情况被称为仿射)。
另一种思考方式:如果网络中没有非线性激活函数,那么无论它有多少层,NN的行为都会像单层感知器一样,因为这些层的求和将给出另一个线性函数(请参见上面的定义)。
>>> in_vec = NP.random.rand(10)
>>> in_vec
array([ 0.94, 0.61, 0.65, 0. , 0.77, 0.99, 0.35, 0.81, 0.46, 0.59])
>>> # common activation function, hyperbolic tangent
>>> out_vec = NP.tanh(in_vec)
>>> out_vec
array([ 0.74, 0.54, 0.57, 0. , 0.65, 0.76, 0.34, 0.67, 0.43, 0.53])
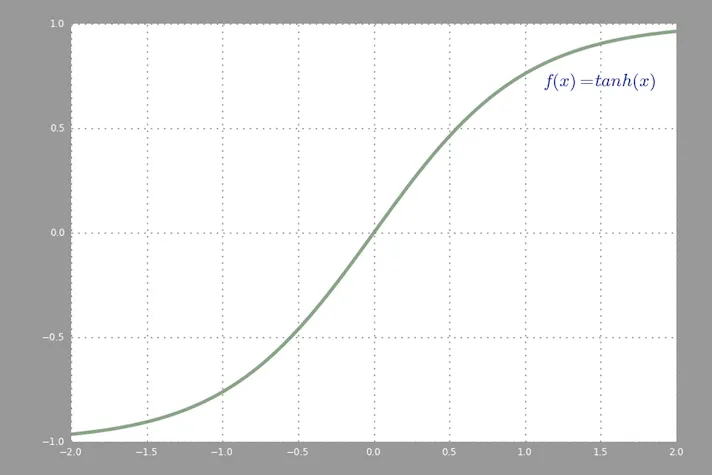
在反向传播中常用的激活函数(双曲正切)在-2到2之间的取值:
f(x) = a*x + c的激活函数,其中a和c是常数,这是线性激活函数的一般化),这将仅导致从输入到输出的affine transformation,这也不是非常令人兴奋。注意: 一个有趣的例外是DeepMind的合成梯度,他们使用一个小的神经网络来预测反向传播过程中的梯度,给定激活值,他们发现可以使用一个没有隐藏层且仅有线性激活的神经网络。

y = h2 * W3 + b3
= (h1 * W2 + b2) * W3 + b3
= h1 * W2 * W3 + b2 * W3 + b3
= (x * W1 + b1) * W2 * W3 + b2 * W3 + b3
= x * W1 * W2 * W3 + b1 * W2 * W3 + b2 * W3 + b3
= x * W' + b'
有时候,一个纯线性的网络可以给出有用的结果。比如说我们有一个三层网络,形状为(3,2,3)。通过将中间层限制在只有两个维度上,我们可以得到一个在原始的三维空间中是“最佳适合平面”的结果。
但是,有更简单的方式来找到这种形式的线性变换,例如NMF,PCA等。然而,在这种情况下,多层网络与单层感知器的行为不同。
W_new = W_old - Learn_rate * D_loss
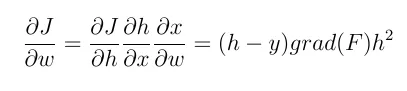
1- 如果激活函数是线性函数,例如:F(x) = 2 * x,则:
"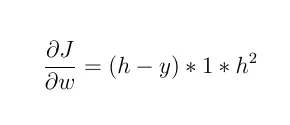
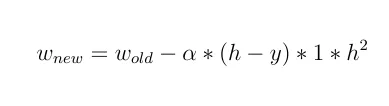
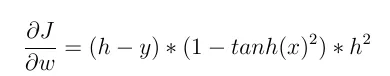
并且: