我正在尝试使用RELU实现神经网络。
输入层-> 1个隐藏层-> relu-> 输出层-> softmax层
以上是我的神经网络架构。 我对这个relu的反向传播感到困惑。 对于RELU的导数,如果x ≤ 0,则输出为0。 如果x> 0,则输出为1。 因此,在计算梯度时,这是否意味着如果x≤0,我会破坏梯度下降?
有人可以逐步解释一下我的神经网络架构的反向传播吗?
我正在尝试使用RELU实现神经网络。
输入层-> 1个隐藏层-> relu-> 输出层-> softmax层
以上是我的神经网络架构。 我对这个relu的反向传播感到困惑。 对于RELU的导数,如果x ≤ 0,则输出为0。 如果x> 0,则输出为1。 因此,在计算梯度时,这是否意味着如果x≤0,我会破坏梯度下降?
有人可以逐步解释一下我的神经网络架构的反向传播吗?
这是一个很好的例子,使用ReLU实现XOR:
参考链接:http://pytorch.org/tutorials/beginner/pytorch_with_examples.html# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
# N is batch size(sample size); D_in is input dimension;
# H is hidden dimension; D_out is output dimension.
N, D_in, H, D_out = 4, 2, 30, 1
# Create random input and output data
x = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y = np.array([[0], [1], [1], [0]])
# Randomly initialize weights
w1 = np.random.randn(D_in, H)
w2 = np.random.randn(H, D_out)
learning_rate = 0.002
loss_col = []
for t in range(200):
# Forward pass: compute predicted y
h = x.dot(w1)
h_relu = np.maximum(h, 0) # using ReLU as activate function
y_pred = h_relu.dot(w2)
# Compute and print loss
loss = np.square(y_pred - y).sum() # loss function
loss_col.append(loss)
print(t, loss, y_pred)
# Backprop to compute gradients of w1 and w2 with respect to loss
grad_y_pred = 2.0 * (y_pred - y) # the last layer's error
grad_w2 = h_relu.T.dot(grad_y_pred)
grad_h_relu = grad_y_pred.dot(w2.T) # the second laye's error
grad_h = grad_h_relu.copy()
grad_h[h < 0] = 0 # the derivate of ReLU
grad_w1 = x.T.dot(grad_h)
# Update weights
w1 -= learning_rate * grad_w1
w2 -= learning_rate * grad_w2
plt.plot(loss_col)
plt.show()
关于ReLU的导数,您可以在这里查看:http://kawahara.ca/what-is-the-derivative-of-relu/
grad_h[h < 0] = 0 # the derivate of ReLU。我理解它的含义。但是,我们是否应该再添加一行代码:grad_h[h > 1] = 1,因为当x>0时,导数为1? - mah65grad_h[h < 0] = 0; grad_h[h > 1] = 1是关于h_relu对h的梯度。 @Belter的代码将grad_h定义为loss相对于h的梯度。根据链式法则,这等于逐元素相乘的grad_h_relu * (h > 0),与grad_h = grad_h_relu.copy(); grad_h[h < 0] = 0相当(但可能更慢)。 - chicxulub当你计算梯度时,如果x≤0,那么意味着我会抑制梯度下降吗?
是的! 如果神经元的输入加权和(激活函数的输入)小于零且使用Relu激活函数,则在反向传播期间导数值为零,这个神经元的输入权重不会更改(不会更新)。
有人能够“分步骤”解释一下我的神经网络架构的反向传播吗?
一个简单的例子可以展示一步反向传播。这个例子覆盖了一步完整的过程。但你也可以只查看与Relu相关的部分。这与问题中介绍的架构类似,为了简单起见,在每层中使用一个神经元。该架构如下:
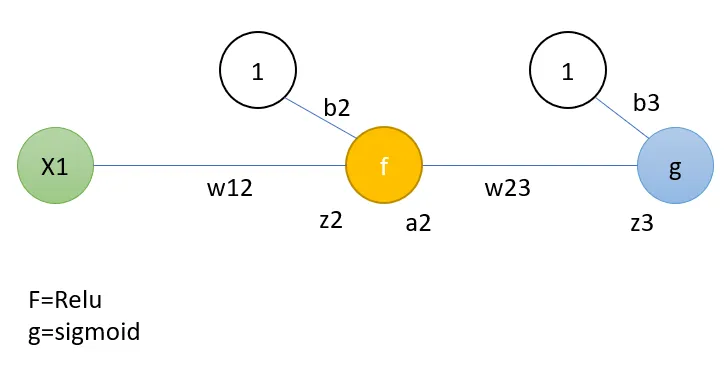
f和g分别表示Relu和sigmoid,b表示偏置。
步骤1: 首先计算输出:
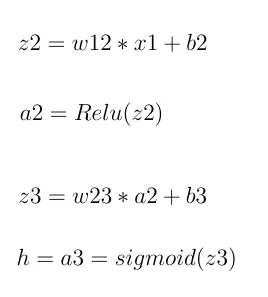
这仅仅代表了输出计算。“z”和“a”分别表示神经元的输入总和和激活函数的输出值。 因此,h是估计值。假设真实值为y。
现在使用反向传播更新权重。
通过计算相对于权重的误差函数的梯度,并从以前的权重中减去该梯度来获得新权重,即:
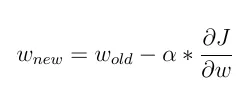
在反向传播中,首先计算最后一层的最后一个神经元的梯度。使用链式法则计算:
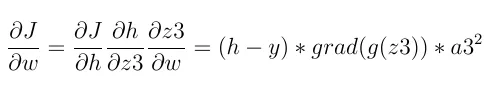
上面使用的三个常规术语是:
实际值与估计值之间的差异
神经元输出的平方
激活函数的导数,鉴于最后一层的激活函数是sigmoid,我们有:
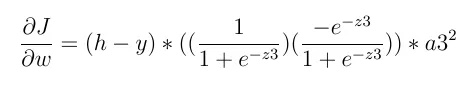
上述语句不一定成为零。
现在我们来到第二层。在第二层中,我们将有:
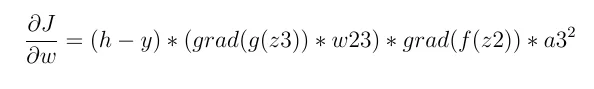
它由四个主要项组成:
实际值与估计值之间的差异。
神经元输出平方
下一层连接的神经元损失导数之和
激活函数的导数,由于激活函数是Relu,所以我们会有:
如果 z2 <= 0 (z2 是 Relu 函数的输入):
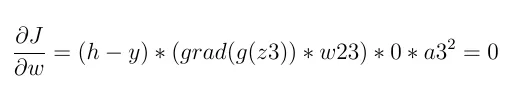
否则,它不一定为零:
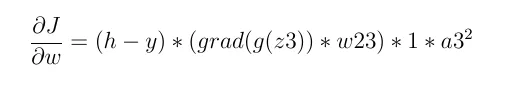
因此,如果神经元的输入小于零,则损失导数始终为零,权重将不会更新。
*必须保证神经元输入之和小于零,才能防止梯度下降过程中的梯度消失。
所提供的示例是为了说明反向传播过程的简单示例。
是的,原来的Relu函数存在您所描述的问题。因此,他们后来对公式进行了修改,并称之为Leaky Relu。本质上,Leaky Relu通过微小的倾斜水平部分的方式稍微改变了函数,获取更多信息,请观看以下内容: