我有一个等级-1的numpy.array,我想制作一个箱线图。然而,我想在数组中排除所有等于零的值。目前,我通过循环该数组并在值不等于零时将其复制到新数组来解决此问题。但是,由于该数组由86,000,000个值组成,我需要多次执行此操作,这需要很多耐心。
是否有更聪明的方法来做到这一点?
对于一个NumPy数组a,您可以使用
a[a != 0]
这是一个需要使用掩码数组的情况,它可以保持数组的形状,并被所有numpy和matplotlib函数自动识别。
X = np.random.randn(1e3, 5)
X[np.abs(X)< .1]= 0 # some zeros
X = np.ma.masked_equal(X,0)
plt.boxplot(X) #masked values are not plotted
#other functionalities of masked arrays
X.compressed() # get normal array with masked values removed
X.mask # get a boolean array of the mask
X.mean() # it automatically discards masked values
我决定比较这里提到的不同方法的运行时间。我使用了我的库simple_benchmark进行测试。
使用array[array!=0]的布尔索引似乎是最快(也是最短)的解决方案。
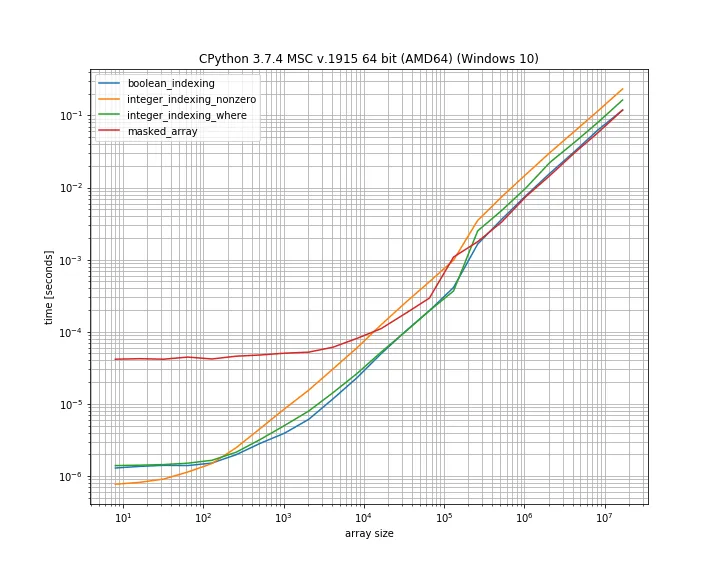
对于较小的数组,MaskedArray方法与其他方法相比非常慢,但与布尔索引方法一样快。但对于中等大小的数组,它们之间并没有太大的区别。
这是我使用的代码:
from simple_benchmark import BenchmarkBuilder
import numpy as np
bench = BenchmarkBuilder()
@bench.add_function()
def boolean_indexing(arr):
return arr[arr != 0]
@bench.add_function()
def integer_indexing_nonzero(arr):
return arr[np.nonzero(arr)]
@bench.add_function()
def integer_indexing_where(arr):
return arr[np.where(arr != 0)]
@bench.add_function()
def masked_array(arr):
return np.ma.masked_equal(arr, 0)
@bench.add_arguments('array size')
def argument_provider():
for exp in range(3, 25):
size = 2**exp
arr = np.random.random(size)
arr[arr < 0.1] = 0 # add some zeros
yield size, arr
r = bench.run()
r.plot()
masked_array的bench构建错误:np.ma.masked_equal(arr, 0)不会返回一个过滤后的数组。应该是m = np.ma.masked_equal(arr, 0); return arr[~m.mask]。 - undefinedA:res = A[A != 0]
bool类型转换,np.nonzero或np.where。以下是一些性能基准测试:# Python 3.7, NumPy 1.14.3
np.random.seed(0)
A = np.random.randint(0, 5, 10**8)
%timeit A[A != 0] # 768 ms
%timeit A[A.astype(bool)] # 781 ms
%timeit A[np.nonzero(A)] # 1.49 s
%timeit A[np.where(A)] # 1.58 s
np.argwhere(*array*)
例子:
import numpy as np
array = [0, 1, 0, 3, 4, 5, 0]
array2 = np.argwhere(array)
print array2
[1, 3, 4, 5]
我建议您在这种情况下使用NaN,这样您就可以忽略一些值,但仍然希望使过程更具统计意义。因此
In []: X= randn(1e3, 5)
In []: X[abs(X)< .1]= NaN
In []: isnan(X).sum(0)
Out[: array([82, 84, 71, 81, 73])
In []: boxplot(X)
a,其中a[k]是一个NumPy数组,所以我想做[a[k][abs(a[k])<.1]=float('NaN') for k in data],但这似乎在循环中失败了,而仅在循环中执行该命令似乎可以工作... - ruben baetensfor k in data: a[k][abs(a[k])< .1]= NaN? - eat[i for i in Array if i != 0.0] 如果数字是浮点数
或者 [i for i in SICER if i != 0] 如果数字是整数。
[i for i in Array if i > 0]。 - Matt
a的维度更高,结果将会是一个扁平化(一维)数组。也可以删除全部为零的列或行。 - Sven Marnacha是一个np.array。这在内置的 Python 数组上不起作用。 - noumenal