我一直在尝试解决这个问题,但一直未能成功。这几乎是与此处至少有一个其他问题重复的,但我无法从相关的在线答案中完全弄清楚我要找的东西。
我有一个Pandas DataFrame(我们称之为df),看起来像是这样:
Name Value Value2
'A' '8.8.8.8' 'x'
'B' '6.6.6.6' 'y'
'A' '6.6.6.6' 'x'
'A' '8.8.8.8' 'x'
其中Name是索引。我希望将其转换为类似于以下的形式:
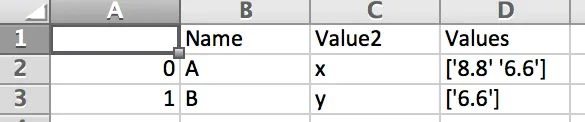
Name Value Value2
'A' ['8.8.8.8', '6.6.6.6'] 'x'
'B' ['6.6.6.6'] 'y'
因此,基本上,与相同索引对应的每个Value应该合并为一个列表(或集合、元组),并将该列表作为相应索引的Value。并且,如所示,Value2 在类似索引的行之间是相同的,因此最终应该保持不变。
我成功地做到的一切就是弄清楚如何将Value列中的每个元素变成列表:
df['Value'] = pd.Series([[val] for val in df['Value']])
在我在本帖开头链接的问题中,合并具有重复索引的列的推荐方法是使用df.groupby(df.index).sum()。 我知道我需要除df.index之外的其他内容作为groupby的参数,因为Value列被视为特殊情况,而我不确定应该放什么来代替sum(),因为那不是我正在寻找的。
希望我正在寻找的内容很清楚,请告诉我是否有什么可以详细说明的地方。 我还尝试简单地遍历DataFrame,查找具有相同索引的行,将Values组合成列表并相应地更新df。在尝试一段时间后,我想找一个更像Pandas方式处理此问题的方法。
编辑:作为对dermen答案的跟进,那个解决方案有些可行。 Values似乎确实正确地连接成了一个列表。 我意识到的一件事是,unique函数返回一个Series,而不是DataFrame。 此外,实际设置中除Name,Value和Value2之外还有更多列。 但我认为我成功地解决了这两个问题,具体如下:
gb = df.groupby(tuple(df.columns.difference(['Value'])))
result = pd.DataFrame(gb['Value'].unique(), columns=df.columns)
第一行将除了 Value 列以外的列作为参数传递给 groupby,第二行将 unique 返回的 Series 转换为一个与 df 相同列的 DataFrame。
但我认为除此之外(除非有人发现问题),几乎所有的功能都能按预期工作。然而,似乎这里有些地方有点不对劲。当我尝试使用 to_csv 将其输出到文件时,顶部有重复的表头(但只有某些表头被重复了,据我所知没有真正的模式)。此外,Value 列的列表被截断了,这可能是一个更简单的问题需要修复。当前的 csv 输出如下:
Name Value Value2 Name Value2
'A' ['8.8.8.8' '7.7.7.7' 'x'
'B' ['6.6.6.6'] 'y'
上面的内容看起来很奇怪,但这正是输出中的样子。请注意,与本帖开头所提供的示例相反,假设有超过2个A的Values(以便我可以说明这一点)。当我使用实际数据进行操作时,Value列表在前4个元素之后被截断。
A不应该有三个值吗? - Padraic Cunninghamdf.drop_duplicates("Value",inplace=True)会删除重复的数据。 - Padraic Cunninghamdf.drop_duplicates(["Name", "Value"])可以解决重复的问题。 - grish