我们搭建了两台完全相同的HP Z840工作站,规格如下:
- 2 x Xeon E5-2690 v4 @ 2.60GHz (Turbo Boost 开启,超线程关闭,总共28个逻辑处理器)
- 32GB DDR4 2400内存,四通道
并在每台机器上安装了Windows 7 SP1 (x64) 和Windows 10 Creators Update (x64)。
然后我们运行了一个小型的内存基准测试(以下是代码),该测试同时从多个线程中执行内存分配、填充和释放操作。
#include <Windows.h>
#include <vector>
#include <ppl.h>
unsigned __int64 ZQueryPerformanceCounter()
{
unsigned __int64 c;
::QueryPerformanceCounter((LARGE_INTEGER *)&c);
return c;
}
unsigned __int64 ZQueryPerformanceFrequency()
{
unsigned __int64 c;
::QueryPerformanceFrequency((LARGE_INTEGER *)&c);
return c;
}
class CZPerfCounter {
public:
CZPerfCounter() : m_st(ZQueryPerformanceCounter()) {};
void reset() { m_st = ZQueryPerformanceCounter(); };
unsigned __int64 elapsedCount() { return ZQueryPerformanceCounter() - m_st; };
unsigned long elapsedMS() { return (unsigned long)(elapsedCount() * 1000 / m_freq); };
unsigned long elapsedMicroSec() { return (unsigned long)(elapsedCount() * 1000 * 1000 / m_freq); };
static unsigned __int64 frequency() { return m_freq; };
private:
unsigned __int64 m_st;
static unsigned __int64 m_freq;
};
unsigned __int64 CZPerfCounter::m_freq = ZQueryPerformanceFrequency();
int main(int argc, char ** argv)
{
SYSTEM_INFO sysinfo;
GetSystemInfo(&sysinfo);
int ncpu = sysinfo.dwNumberOfProcessors;
if (argc == 2) {
ncpu = atoi(argv[1]);
}
{
printf("No of threads %d\n", ncpu);
try {
concurrency::Scheduler::ResetDefaultSchedulerPolicy();
int min_threads = 1;
int max_threads = ncpu;
concurrency::SchedulerPolicy policy
(2 // two entries of policy settings
, concurrency::MinConcurrency, min_threads
, concurrency::MaxConcurrency, max_threads
);
concurrency::Scheduler::SetDefaultSchedulerPolicy(policy);
}
catch (concurrency::default_scheduler_exists &) {
printf("Cannot set concurrency runtime scheduler policy (Default scheduler already exists).\n");
}
static int cnt = 100;
static int num_fills = 1;
CZPerfCounter pcTotal;
// malloc/free
printf("malloc/free\n");
{
CZPerfCounter pc;
for (int i = 1 * 1024 * 1024; i <= 8 * 1024 * 1024; i *= 2) {
concurrency::parallel_for(0, 50, [i](size_t x) {
std::vector<void *> ptrs;
ptrs.reserve(cnt);
for (int n = 0; n < cnt; n++) {
auto p = malloc(i);
ptrs.emplace_back(p);
}
for (int x = 0; x < num_fills; x++) {
for (auto p : ptrs) {
memset(p, num_fills, i);
}
}
for (auto p : ptrs) {
free(p);
}
});
printf("size %4d MB, elapsed %8.2f s, \n", i / (1024 * 1024), pc.elapsedMS() / 1000.0);
pc.reset();
}
}
printf("\n");
printf("Total %6.2f s\n", pcTotal.elapsedMS() / 1000.0);
}
return 0;
}
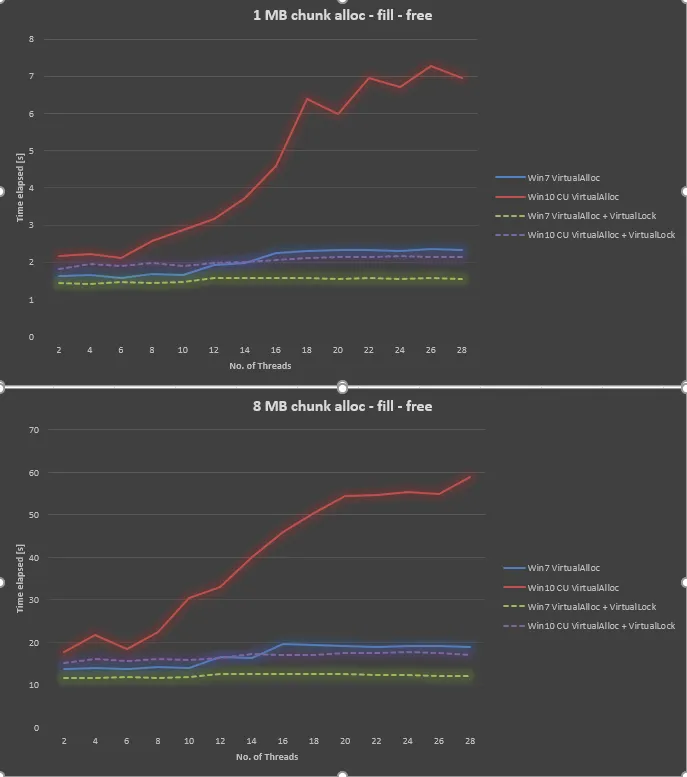
令人惊讶的是,在Windows 10 CU中,结果与Windows 7相比非常糟糕。 我绘制了以下1MB块大小和8MB块大小的结果,将线程数从2,4,..变化到28。 当我们增加线程数时,虽然Windows 7的性能略微差一些,但Windows 10的可扩展性要差得多。
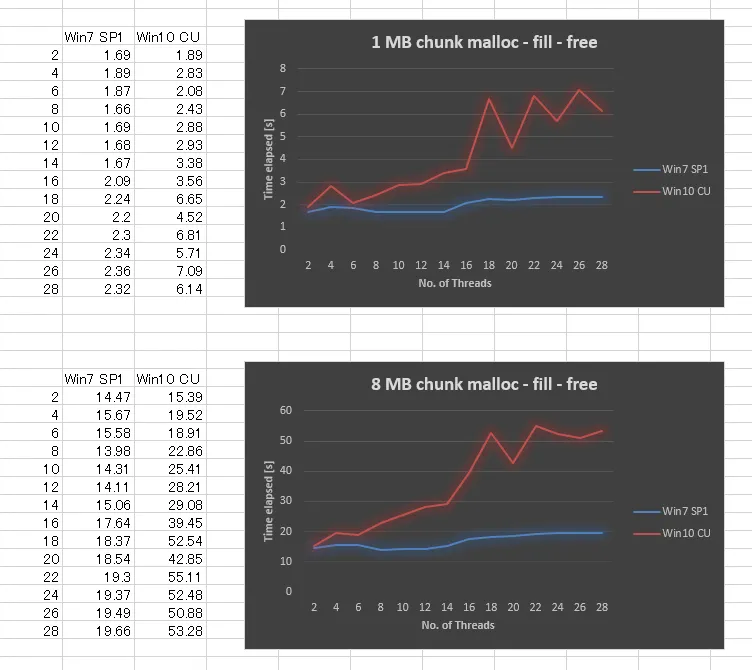
我们已经尝试确保应用了所有Windows更新、更新了驱动程序、调整了BIOS设置,但都没有成功。我们还在几个其他硬件平台上运行了相同的基准测试,并且所有的测试结果表明Windows 10的曲线类似。因此,这似乎是Windows 10的问题。
是否有人有类似的经验,或者可能了解这个问题(也许我们遗漏了什么?)。这种行为使我们的多线程应用程序受到了显着的性能损失。
***编辑
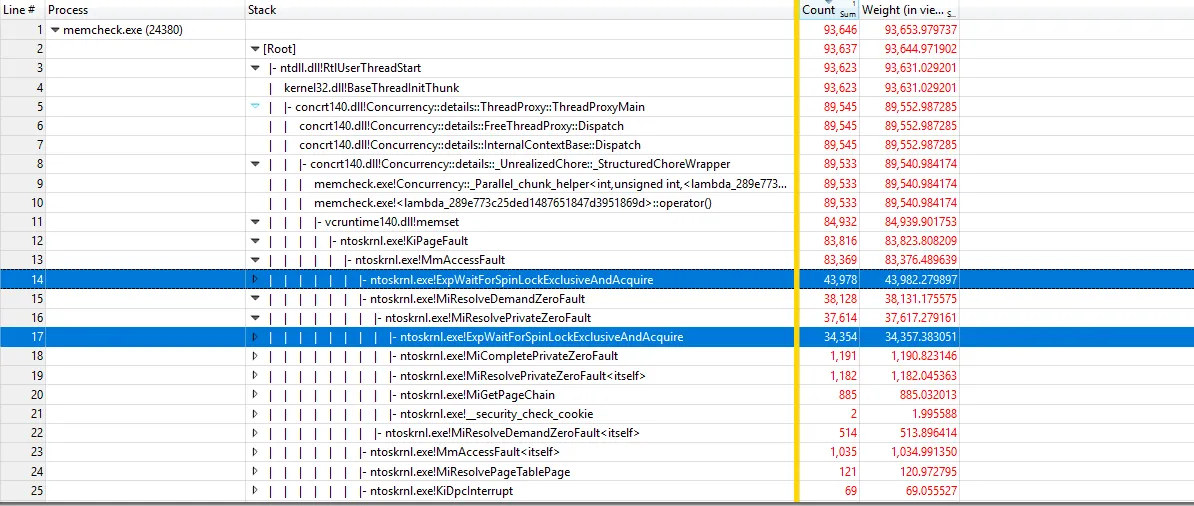
使用https://github.com/google/UIforETW(感谢Bruce Dawson)分析基准测试,我们发现大部分时间都花在内核的KiPageFault中。进一步钻下调用树,所有的线索都指向ExpWaitForSpinLockExclusiveAndAcquire。看来锁争用导致了这个问题。
***编辑
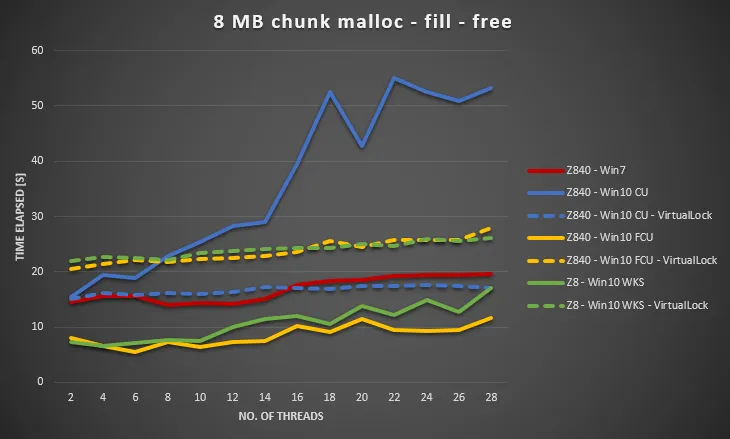
在相同的硬件上收集Server 2012 R2数据。 Server 2012 R2也不如Win7,但比Win10 CU好得多。
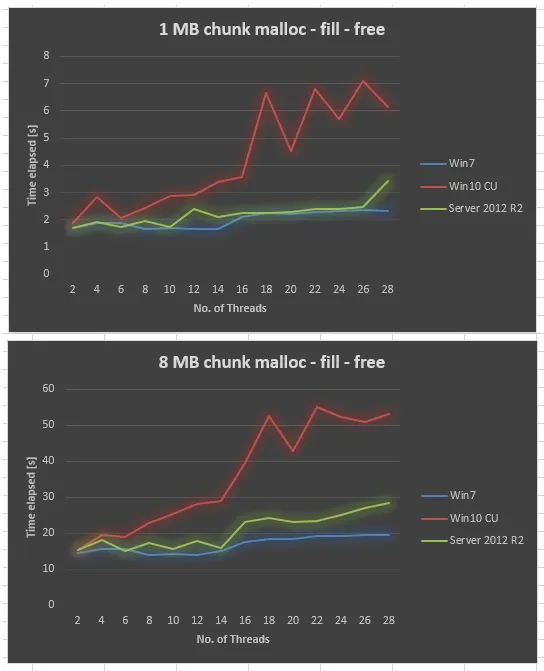
***编辑
这也发生在Server 2016中。我添加了标签windows-server-2016。
***编辑
使用@Ext3h提供的信息,我修改了基准测试以使用VirtualAlloc和VirtualLock。我可以证实与不使用VirtualLock时相比,有显着的改进。总体而言,当使用VirtualAlloc和VirtualLock时,Win10仍然比Win7慢30%至40%。