我在Windows下遇到了线程问题。
我正在开发一个程序,为不同的条件运行复杂的物理模拟。比如每年的每个小时都有一个条件,就需要进行8760次模拟。我将这些模拟按线程分组,使得每个线程运行平均273个模拟的for循环。
我买了一台AMD ryzen 9 5950x电脑,有16个核心(32个线程)用于这个任务。在Linux上,所有线程的利用率似乎都在98%到100%之间,而在Windows下我得到了这个:
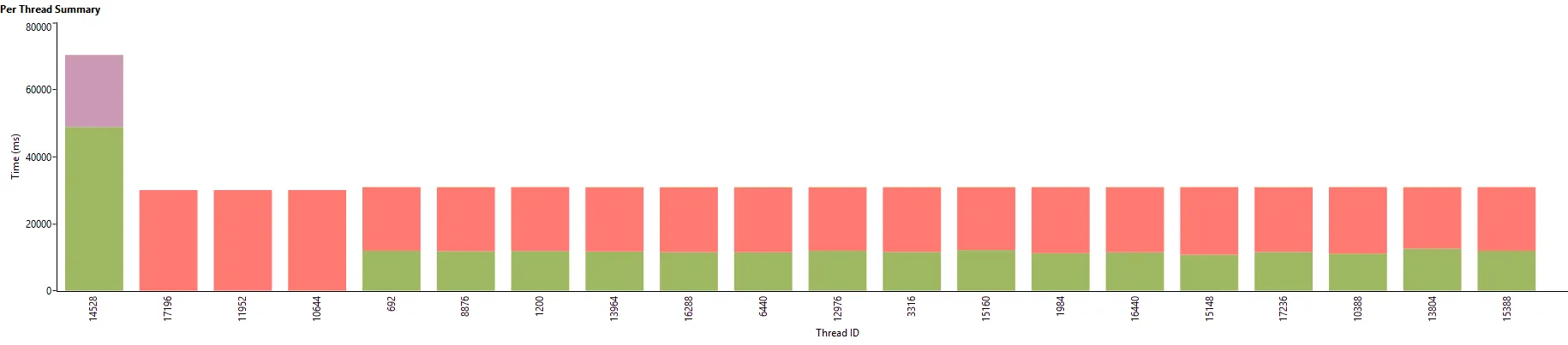 (第一个条是读取数据的I/O线程,较小的条是进程线程。红色:同步,绿色:进程,紫色:I/O)
(第一个条是读取数据的I/O线程,较小的条是进程线程。红色:同步,绿色:进程,紫色:I/O)
这是来自Visual Studio的并发可视化器,它告诉我63%的时间花费在线程同步上。据我所知,我的代码在Linux和Windows的执行中是相同的。
我尽力使对象不可变以避免问题,并且在旧的8线程Intel i7上提供了巨大的收益。但是使用更多的线程,这个问题就出现了。
对于线程,我尝试过自定义的parallel for和taskflow库。对于我想要做的事情,两者表现一致。
是不是Windows线程本质上存在某些会导致这种行为的问题?
自定义的parallel for代码:
/**
* parallel for
* @tparam Index integer type
* @tparam Callable function type
* @param start start index of the loop
* @param end final +1 index of the loop
* @param func function to evaluate
* @param nb_threads number of threads, if zero, it is determined automatically
*/
template<typename Index, typename Callable>
static void ParallelFor(Index start, Index end, Callable func, unsigned nb_threads=0) {
// Estimate number of threads in the pool
if (nb_threads == 0) nb_threads = getThreadNumber();
// Size of a slice for the range functions
Index n = end - start + 1;
Index slice = (Index) std::round(n / static_cast<double> (nb_threads));
slice = std::max(slice, Index(1));
// [Helper] Inner loop
auto launchRange = [&func] (int k1, int k2) {
for (Index k = k1; k < k2; k++) {
func(k);
}
};
// Create pool and launch jobs
std::vector<std::thread> pool;
pool.reserve(nb_threads);
Index i1 = start;
Index i2 = std::min(start + slice, end);
for (unsigned i = 0; i + 1 < nb_threads && i1 < end; ++i) {
pool.emplace_back(launchRange, i1, i2);
i1 = i2;
i2 = std::min(i2 + slice, end);
}
if (i1 < end) {
pool.emplace_back(launchRange, i1, end);
}
// Wait for jobs to finish
for (std::thread &t : pool) {
if (t.joinable()) {
t.join();
}
}
}
这里上传了一个完整的C++项目,涉及到技术问题,请点击此处
Main.cpp:
//
// Created by santi on 26/08/2022.
//
#include "input_data.h"
#include "output_data.h"
#include "random.h"
#include "par_for.h"
void fillA(Matrix& A){
Random rnd;
rnd.setTimeBasedSeed();
for(int i=0; i < A.getRows(); ++i)
for(int j=0; j < A.getRows(); ++j)
A(i, j) = (int) rnd.randInt(0, 1000);
}
void worker(const InputData& input_data,
OutputData& output_data,
const std::vector<int>& time_indices,
int thread_index){
std::cout << "Thread " << thread_index << " [" << time_indices[0]<< ", " << time_indices[time_indices.size() - 1] << "]\n";
for(const int& t: time_indices){
Matrix b = input_data.getAt(t);
Matrix A(input_data.getDim(), input_data.getDim());
fillA(A);
Matrix x = A * b;
output_data.setAt(t, x);
}
}
void process(int time_steps, int dim, int n_threads){
InputData input_data(time_steps, dim);
OutputData output_data(time_steps, dim);
// correct the number of threads
if ( n_threads < 1 ) { n_threads = ( int )getThreadNumber( ); }
// generate indices
std::vector<int> time_indices = arrange<int>(time_steps);
// compute the split of indices per core
std::vector<ParallelChunkData<int>> chunks = prepareParallelChunks(time_indices, n_threads );
// run in parallel
ParallelFor( 0, ( int )chunks.size( ), [ & ]( int k ) {
// run chunk
worker(input_data, output_data, chunks[k].indices, k );
} );
}
int main(){
process(8760, 5000, 0);
return 0;
}
join只影响调用线程之外,这里没有展示任何同步。如果出现问题,很可能是您传递的func函数有问题。 - François Andrieuxfunc是做什么的?乍一看,它似乎只是在func中的“用户”代码简单地访问来自其他线程的资源阻塞构造。无论是分页内存页面、等待互斥锁、设备的 IO 等等。如果没有看到func的实际操作,或者没有将func替换为一个简单的计算,很难得出结论(是的,就像 François 更快地说的那样 :-))。 - Jeffreystd::for_each(std::execution::par_unseq,...吗?这可能比自己操作产生更好的结果。因为你很可能因为标准库中std::thread的工作方式而遇到创建线程的开销问题。标准库可以利用诸如 Windows 线程池之类的东西来降低这种成本。在 Windows 上,线程非常昂贵(由于各种原因,Linus 后悔没有实现它们),因此它们意味着要持续一段时间。 - Mgetz