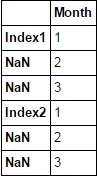
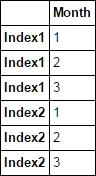
我有一个Excel文件,其中的索引跨越了几行并在Excel中合并。当我在pandas中加载它时,它将第一行读作索引标签,而其余部分(合并单元格)则填充为NaN。如何循环遍历索引以便使用相应的索引填充NaN?
import pandas as pd
df = pd.read_excel('myexcelfile.xlsx', header=1)
df.head()
Index-header Month
0 Index1 1
1 NaN 2
2 NaN 3
3 NaN 4
4 NaN 5
5 Index2 1
6 NaN 2
...