我有一个上三角矩阵(不包括对角线),如下:
M = [0 3 2 2 0 0; 0 0 8 6 3 2; 0 0 0 3 2 1; 0 0 0 0 2 1; 0 0 0 0 0 0]
生成的矩阵应该长这样:
R = [0 0 0 0 0 0; 0 2 0 0 0 0; 2 3 1 0 0 0; 2 6 2 1 0 0; 3 8 3 2 0 0]
由于我找不到一个简单的解释来描述我的目标,因此我尝试用图像来可视化它:
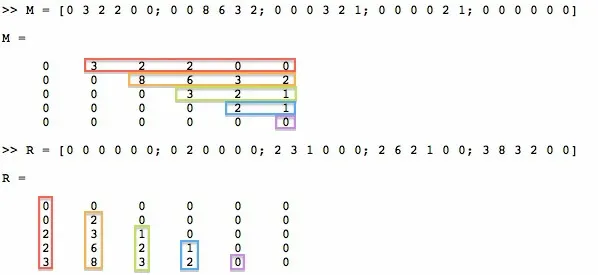
我已经尝试了许多不同的组合,如rot90、transpose、flipud等,但我找不到正确的转换方式,使我得到矩阵R
编辑:
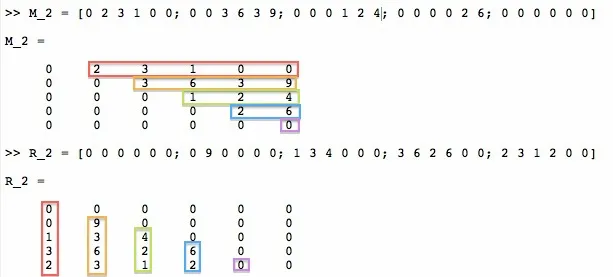
矩阵M的行并不总是像上面的示例那样排序。对于另一个矩阵M_2:
M_2 = [0 2 3 1 0 0; 0 0 3 6 3 9; 0 0 0 1 2 4; 0 0 0 0 2 6; 0 0 0 0 0 0]
生成的矩阵 R_2 需要如下所示:
R_2 = [0 0 0 0 0 0; 0 9 0 0 0 0; 1 3 4 0 0 0; 3 6 2 6 0 0; 2 3 1 2 0 0]
再次展示下面的可视化图表:
sort(M')怎么样? - Dansort似乎是一个不错的开始。 - Schnigges