我一直在尝试使用Keras实现一个简单的线性回归模型,希望能够理解Keras库的工作原理。不幸的是,我的模型表现非常糟糕。以下是我的实现代码:
from pylab import *
from keras.models import Sequential
from keras.layers import Dense
#Generate dummy data
data = data = linspace(1,2,100).reshape(-1,1)
y = data*5
#Define the model
def baseline_model():
model = Sequential()
model.add(Dense(1, activation = 'linear', input_dim = 1))
model.compile(optimizer = 'rmsprop', loss = 'mean_squared_error', metrics = ['accuracy'])
return model
#Use the model
regr = baseline_model()
regr.fit(data,y,epochs =200,batch_size = 32)
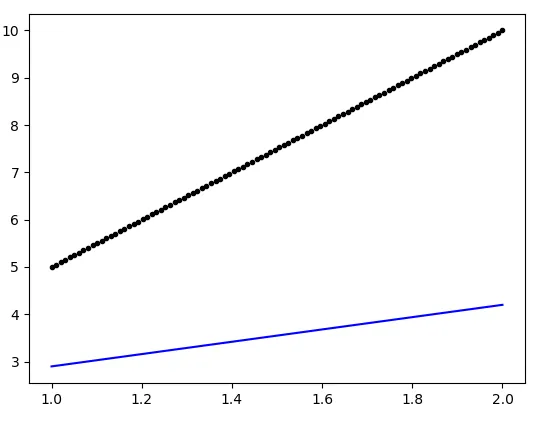
plot(data, regr.predict(data), 'b', data,y, 'k.')
生成的图如下:
{kind=link}
{kind=link}
{kind=link}
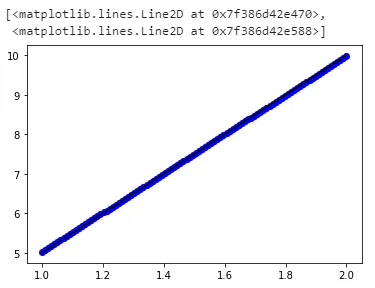{kind=link}
optimizers.SGD()并且学习率设置为lr=0.1。我估计,使用 SGD 后经过 200 个 epoch,您将达到约为1e-4或1e-5的损失。但由于优化过程是逐步进行的,而不是明确的,因此不要期望达到精确的零损失。 - today