我有两个感知机算法,它们完全相同,唯一的区别是激活函数。一个使用单步函数
我本来期望tanh函数表现更好,但实际上与单步函数相比表现很差。我是否做错了什么,还是这个问题集下它表现不佳有原因?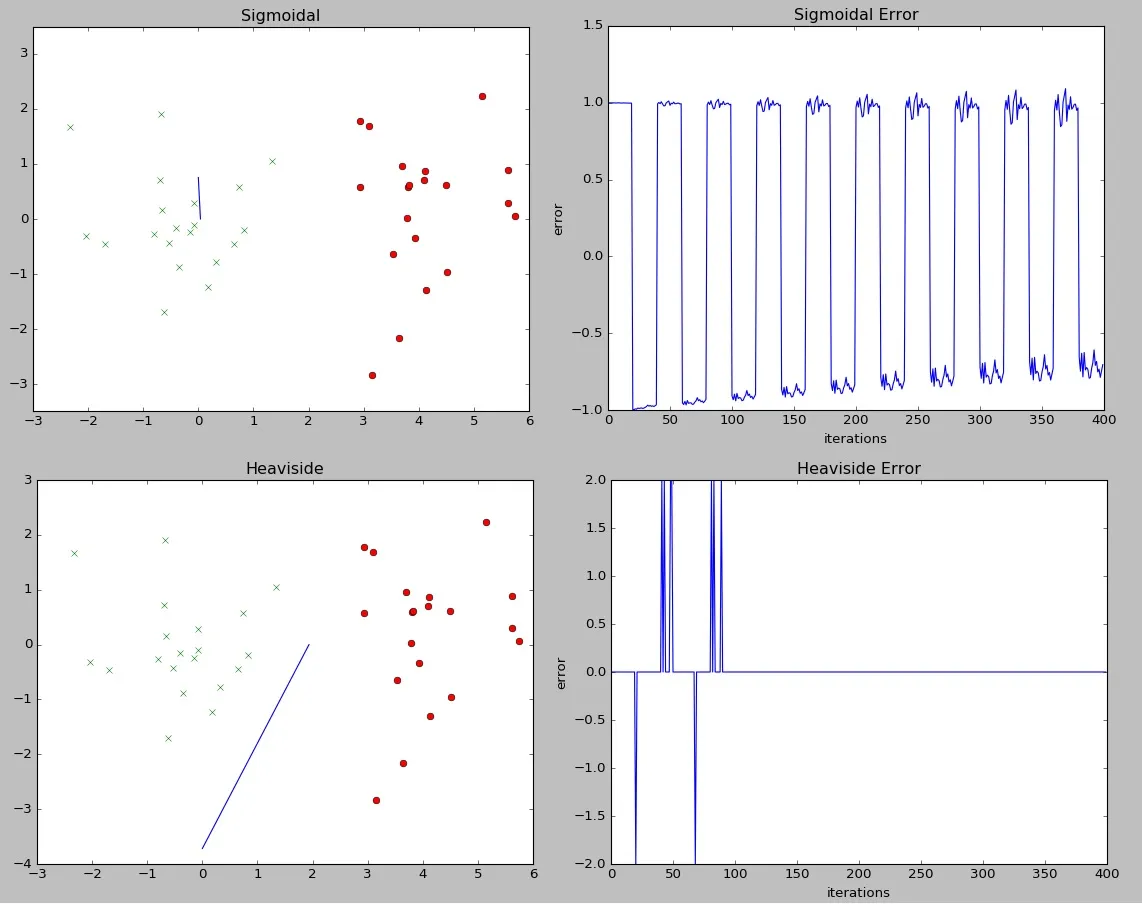
1 if u >= 0 else -1,另一个则利用tanh函数np.tanh(u)。我本来期望tanh函数表现更好,但实际上与单步函数相比表现很差。我是否做错了什么,还是这个问题集下它表现不佳有原因?
import numpy as np
import matplotlib.pyplot as plt
# generate 20 two-dimensional training data
# data must be linearly separable
# C1: u = (0,0) / E = [1 0; 0 1]; C2: u = (4,0), E = [1 0; 0 1] where u, E represent centre & covariance matrix of the
# Gaussian distribution respectively
def step(u):
return 1 if u >= 0 else -1
def sigmoid(u):
return np.tanh(u)
c1mean = [0, 0]
c2mean = [4, 0]
c1cov = [[1, 0], [0, 1]]
c2cov = [[1, 0], [0, 1]]
x = np.ones((40, 3))
w = np.zeros(3) # [0, 0, 0]
w2 = np.zeros(3) # second set of weights to see how another classifier compares
t = [] # target array
# +1 for the first 20 then -1
for i in range(0, 40):
if i < 20:
t.append(1)
else:
t.append(-1)
x1, y1 = np.random.multivariate_normal(c1mean, c1cov, 20).T
x2, y2 = np.random.multivariate_normal(c2mean, c2cov, 20).T
# concatenate x1 & x2 within the first dimension of x and the same for y1 & y2 in the second dimension
for i in range(len(x)):
if i >= 20:
x[i, 0] = x2[(i-20)]
x[i, 1] = y2[(i-20)]
else:
x[i, 0] = x1[i]
x[i, 1] = y1[i]
errors = []
errors2 = []
lr = 0.0001
n = 10
for i in range(n):
count = 0
for row in x:
dot = np.dot(w, row)
response = step(dot)
errors.append(t[count] - response)
w += lr * (row * (t[count] - response))
count += 1
for i in range(n):
count = 0
for row in x:
dot = np.dot(w2, row)
response = sigmoid(dot)
errors2.append(t[count] - response)
w2 += lr * (row * (t[count] - response))
count += 1
print(errors[-1], errors2[-1])
# distribution
plt.figure(1)
plt.plot((-(w[2]/w[0]), 0), (0, -(w[2]/w[1])))
plt.plot(x1, y1, 'x')
plt.plot(x2, y2, 'ro')
plt.axis('equal')
plt.title('Heaviside')
# training error
plt.figure(2)
plt.ylabel('error')
plt.xlabel('iterations')
plt.plot(errors)
plt.title('Heaviside Error')
plt.figure(3)
plt.plot((-(w2[2]/w2[0]), 0), (0, -(w2[2]/w2[1])))
plt.plot(x1, y1, 'x')
plt.plot(x2, y2, 'ro')
plt.axis('equal')
plt.title('Sigmoidal')
plt.figure(4)
plt.ylabel('error')
plt.xlabel('iterations')
plt.plot(errors2)
plt.title('Sigmoidal Error')
plt.show()
编辑:即使从我展示的错误图中,tanh函数也显示出一些收敛性,因此可以合理地假设仅增加迭代次数或减小学习率就可以使其减少误差。然而,我想问的是,考虑到阶跃函数的显着更好的性能,在哪些问题集上使用具有Perceptron的tanh函数是可行的?
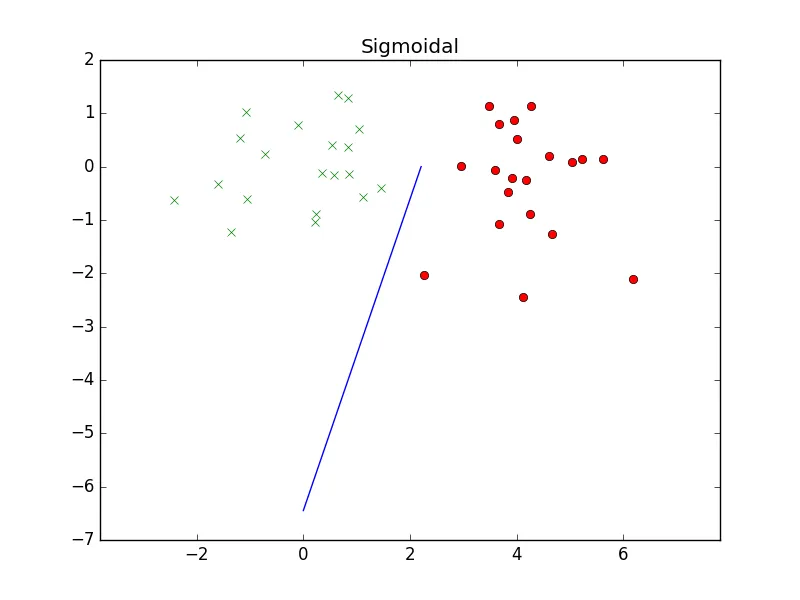
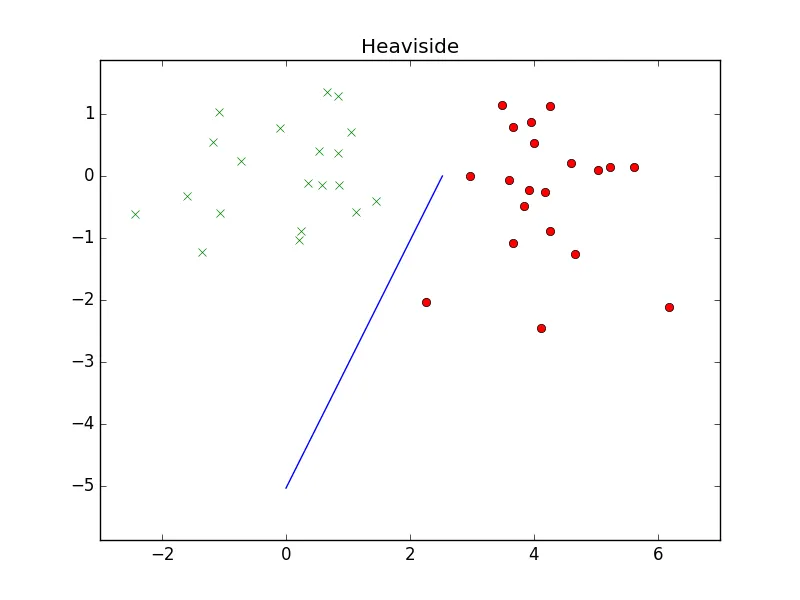
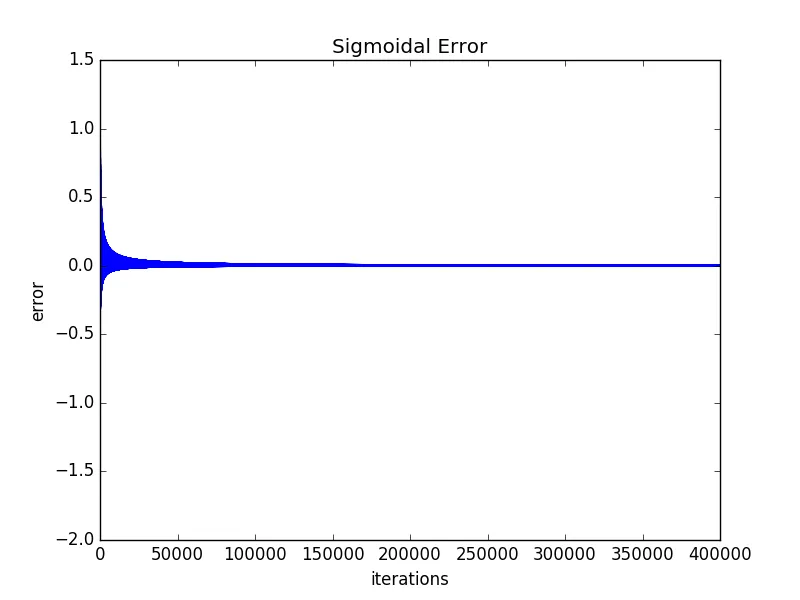
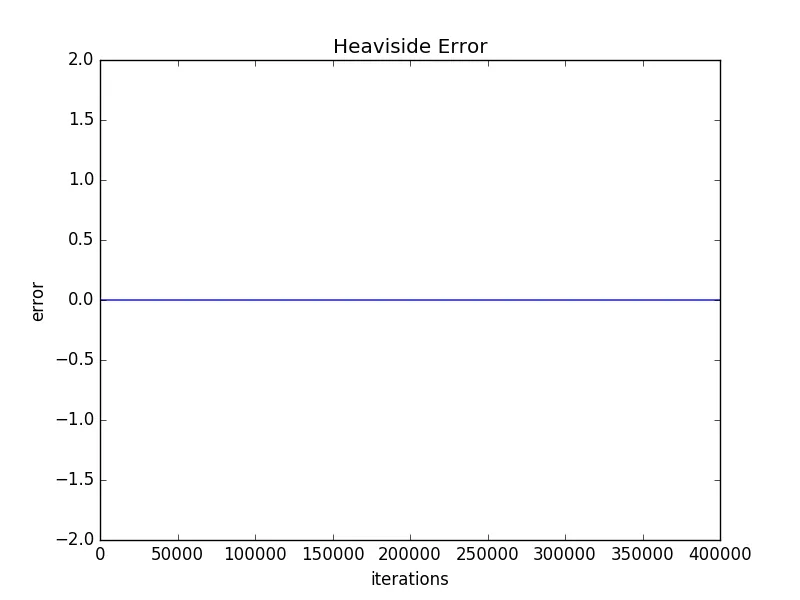
lr更改为0.1或1时,结果看起来几乎相同,因此你的学习率太小了。 - Clebn。 - Cleb