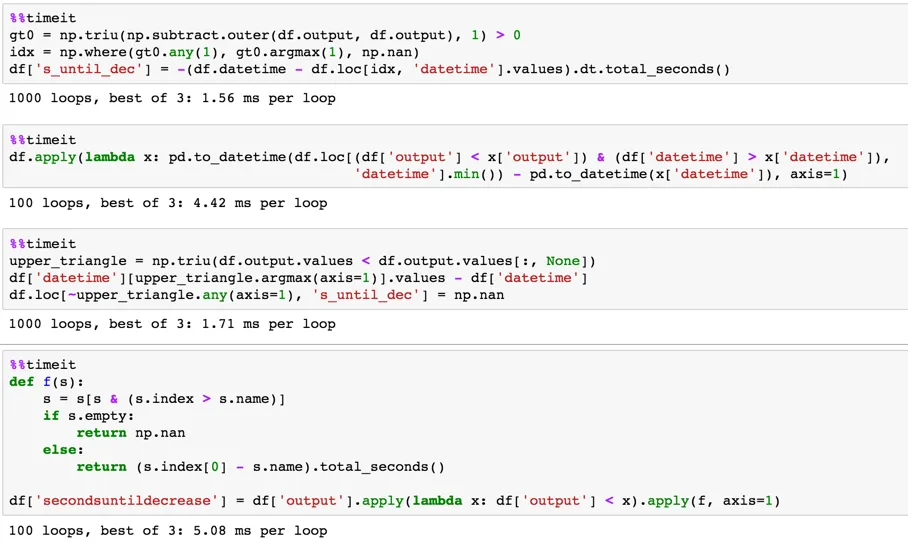
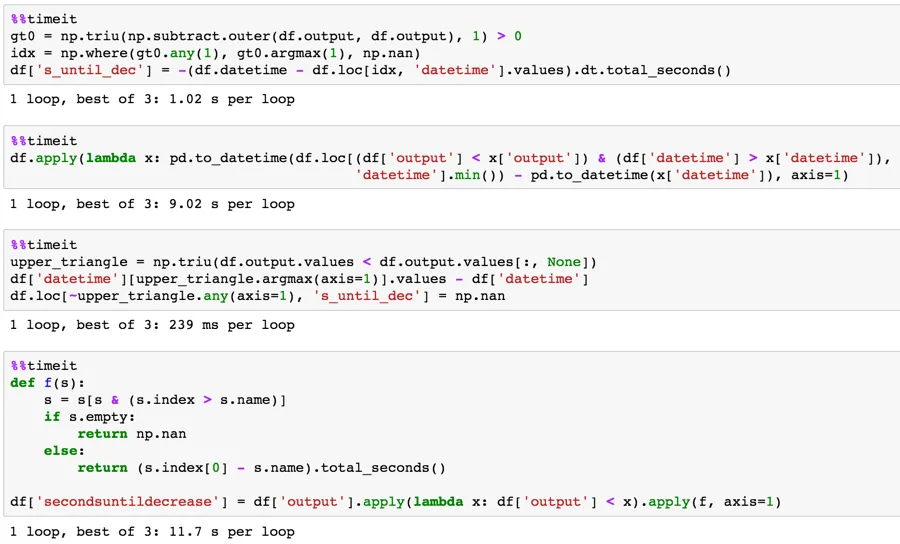
我有一个Python中的Pandas数据框,其中有几列和一个日期时间戳。我想创建一个新列,计算输出时间小于当前周期时间的时间。
我的当前表格大致如下:
datetime output
2014-05-01 01:00:00 3
2014-05-01 01:00:01 2
2014-05-01 01:00:02 3
2014-05-01 01:00:03 2
2014-05-01 01:00:04 1
我正在尝试为我的表格增加一列,并让它看起来像这样:
datetime output secondsuntildecrease
2014-05-01 01:00:00 3 1
2014-05-01 01:00:01 2 3
2014-05-01 01:00:02 3 1
2014-05-01 01:00:03 2 1
2014-05-01 01:00:04 1
感谢您的提前帮助!