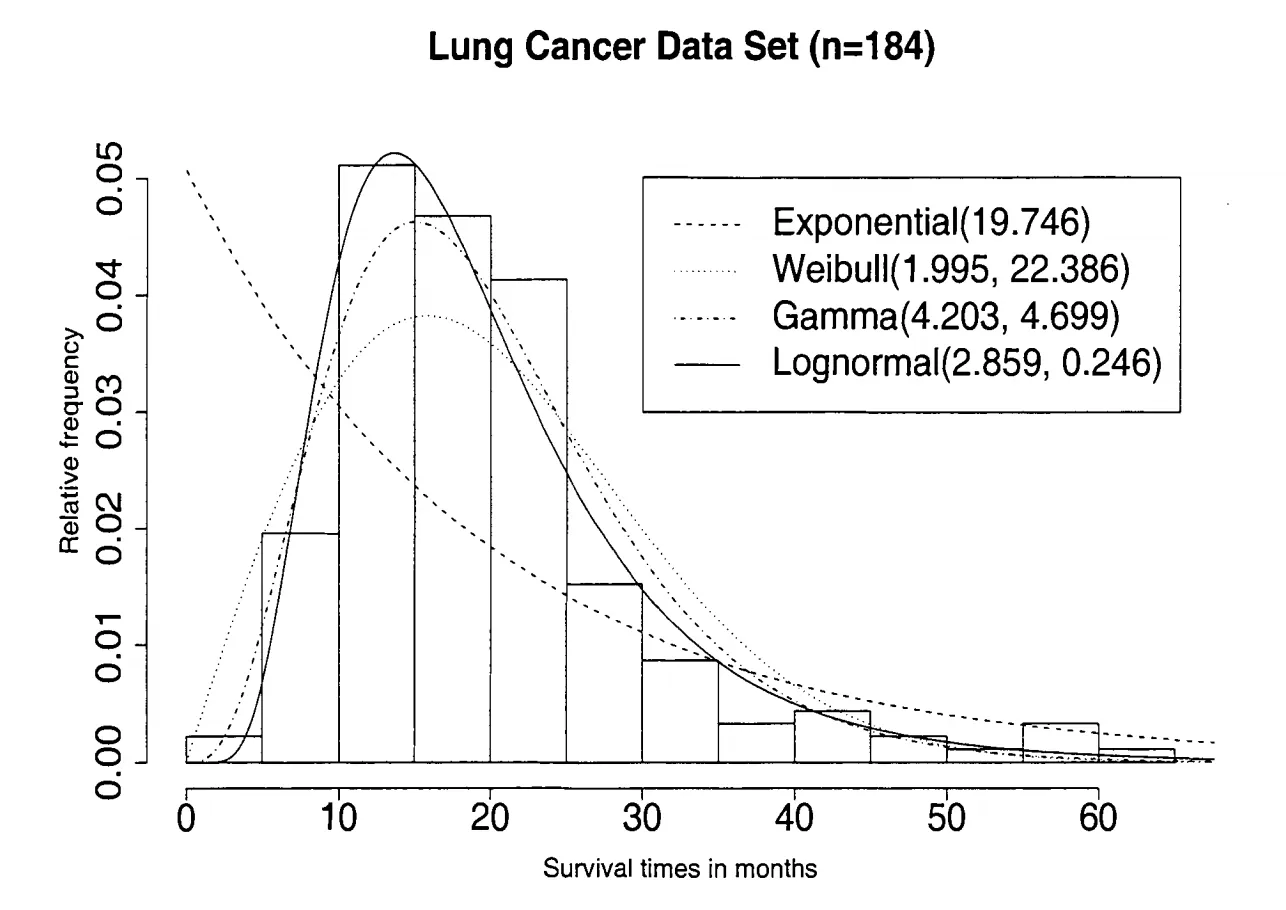
log(time)上方。文本所述的图像显示了每个模型的拟合并获得了以下参数:
survreg(Surv(time,event)~1,dist="family")
cbind将它们组合起来,但我更感兴趣的是从拟合模型中调用它们。survreg对象存储系数估计值,但调用survreg.obj$coefficients会得到一个命名的数字向量(而不是一个数字)。 ”
“4)最重要的是,我该如何绘制类似的图形?如果我只提取参数并在直方图上绘制它们,那么我认为这将非常简单,但是迄今为止没有运气。文本的作者说他从参数估计了密度曲线,但我只得到了点估计 - 我错过了什么?我应该在绘图之前根据分布手动计算密度曲线吗?”
我不确定如何在这种情况下提供一个最小工作示例,但老实说,我只需要一个通用的解决方案来将多个密度曲线添加到生存数据中。另一方面,如果您认为这会有所帮助,请随便推荐一个最小工作示例的解决方案,我会尝试制作一个。
感谢您的建议!
编辑:根据eclark的帖子,我已经取得了一些进展。我的参数是:
Dist = data.frame(
Exponential = rweibull(n = 10000, shape = 1, scale = 6.636684),
Weibull = rweibull(n = 10000, shape = 6.068786, scale = 2.002165),
Gamma = rgamma(n = 10000, shape = 768.1476, scale = 1433.986),
LogNormal = rlnorm(n = 10000, meanlog = 4.986, sdlog = .877)
)
summary(fit.exp)
Call:
survreg(formula = Surv(duration, confterm) ~ 1, data = data.na,
dist = "exponential")
Value Std. Error z p
(Intercept) 6.64 0.052 128 0
Scale fixed at 1
Exponential distribution
Loglik(model)= -2825.6 Loglik(intercept only)= -2825.6
Number of Newton-Raphson Iterations: 6
n= 397
summary(fit.wei)
Call:
survreg(formula = Surv(duration, confterm) ~ 1, data = data.na,
dist = "weibull")
Value Std. Error z p
(Intercept) 6.069 0.1075 56.5 0.00e+00
Log(scale) 0.694 0.0411 16.9 6.99e-64
Scale= 2
Weibull distribution
Loglik(model)= -2622.2 Loglik(intercept only)= -2622.2
Number of Newton-Raphson Iterations: 6
n= 397
summary(fit.gau)
Call:
survreg(formula = Surv(duration, confterm) ~ 1, data = data.na,
dist = "gaussian")
Value Std. Error z p
(Intercept) 768.15 72.6174 10.6 3.77e-26
Log(scale) 7.27 0.0372 195.4 0.00e+00
Scale= 1434
Gaussian distribution
Loglik(model)= -3243.7 Loglik(intercept only)= -3243.7
Number of Newton-Raphson Iterations: 4
n= 397
summary(fit.log)
Call:
survreg(formula = Surv(duration, confterm) ~ 1, data = data.na,
dist = "lognormal")
Value Std. Error z p
(Intercept) 4.986 0.1216 41.0 0.00e+00
Log(scale) 0.877 0.0373 23.5 1.71e-122
Scale= 2.4
Log Normal distribution
Loglik(model)= -2624 Loglik(intercept only)= -2624
Number of Newton-Raphson Iterations: 5
n= 397
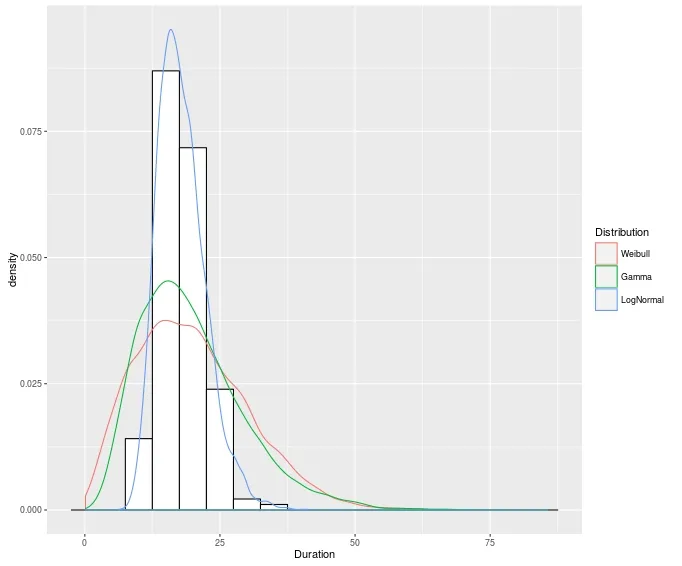
?survreg.distributions,其中有一条评论指出生存Weibull分布的参数化方式与rweibull中的不同。我也完全不确定你是否正确地进行了Gamma参数化 - 这似乎比对数正态分布更偏离。 - Gregor Thomas