如果某行符合条件,我想要创建一个重复的行。在下面的表格中,我基于分组创建了一个累积计数,然后进行了另一个分组最大值的计算。
df['PathID'] = df.groupby(DateCompleted).cumcount() + 1
df['MaxPathID'] = df.groupby(DateCompleted)['PathID'].transform(max)
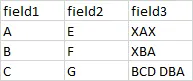
Date Completed PathID MaxPathID
1/31/17 1 3
1/31/17 2 3
1/31/17 3 3
2/1/17 1 1
2/2/17 1 2
2/2/17 2 2
在这种情况下,我只想复制2/1/17的记录,因为该日期只有一个实例(即MaxPathID == 1的实例)。
期望输出:
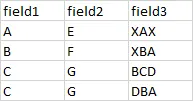
Date Completed PathID MaxPathID
1/31/17 1 3
1/31/17 2 3
1/31/17 3 3
2/1/17 1 1
2/1/17 1 1
2/2/17 1 2
2/2/17 2 2
提前感谢您!
2/1/17的重复项。输出中的行与原始行在 PathID 和 MaxPathID 上有所不同。请准确说明您想要获得什么(不是通过示例,而是通过算法)。 - DYZMaxPathID的呢? - gold_cydf.append(df[df['MaxPathID']==1])创建完全相同的副本,但显然这不是你想要的。 - DYZ