我有以下数据框:
In [62]: df
Out[62]:
coverage name reports year
Cochice 45 Jason 4 2012
Pima 214 Molly 24 2012
Santa Cruz 212 Tina 31 2013
Maricopa 72 Jake 2 2014
Yuma 85 Amy 3 2014
基本上我可以按照以下方式筛选行:
df[df["coverage"] > 30
我可以按照下面的方法删除一行数据:
df.drop(['Cochice', 'Pima'])
但是我想根据条件删除若干行,我该怎么做呢?
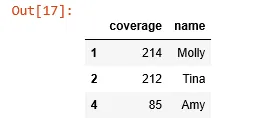
df[df["coverage"] >= 72]。 - jezrael