我考虑将HashMap作为QuadTree的后备结构。我相信我可以使用莫顿序列来唯一地标识我感兴趣的每个方块。我知道我的QuadTree最多会有16层。根据我的计算,这将导致一个65,536 x 65,536的矩阵,这应该至多给我4,294,967,296个单元格。有人知道这对于HashMap来说是否太多了吗?我总是可以编写一个使用树的QuadTree,但我认为使用HashMap可以获得更好的性能。
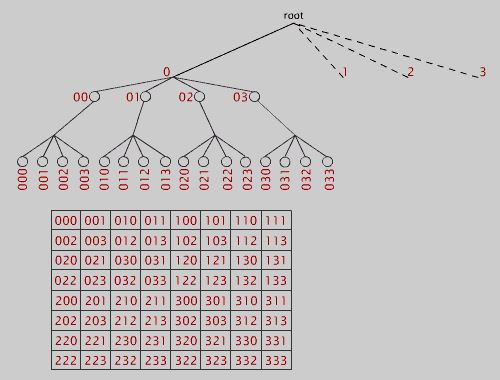
高度为1的莫顿序列==(2x2)== 4
高度为2的莫顿序列==(4x4)== 16
高度为3的莫顿序列==(8x8)== 64
用于最大高度为3的树的莫顿序列示例。
以下是我知道的内容:
- 我将在已知矩形区域内获得经纬度数据。
- 数据不会完全覆盖整个区域,并且很可能会被合并成该区域的某些部分。(最坏情况是所有4,294,967,296个单元格中都有数据)
- 数据的分辨率最终会将该区域分解为65k x 65k的矩形。
- 我还知道,插入/更新数据的查询很可能是10比1。