我有一组各地位置的纬度和经度信息,也知道我的当前位置的纬度和经度。我需要找出最靠近我的当前位置的地点。
- Kdtree和quadtree中哪个算法是从纬度和经度信息集中查找邻近位置最好的?
- 其中一个算法相对于另一个算法的优点是什么?
- 我们如何在C#中实现这些算法以实现上述目的?
Note: "Kdtree" 和 "quadtree" 翻译为“kd树”和“四叉树”,通常用于计算机科学和数据结构中。
我有一组各地位置的纬度和经度信息,也知道我的当前位置的纬度和经度。我需要找出最靠近我的当前位置的地点。
比较空间索引技术,我想把第三种称为网格索引的方法加入我们的比较研究中。为了理解四叉树,我想先介绍网格索引。
什么是网格索引?
网格索引是一种基于网格的空间索引方法,其中研究区域被划分为固定大小的瓦片(固定尺寸,如棋盘格)。
使用网格索引,每个瓦片中的每个点都带有该瓦片编号的标记,因此索引表可以为每个点提供一个标签,显示该点所在的瓦片号码。
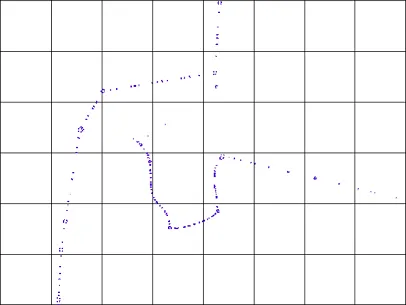
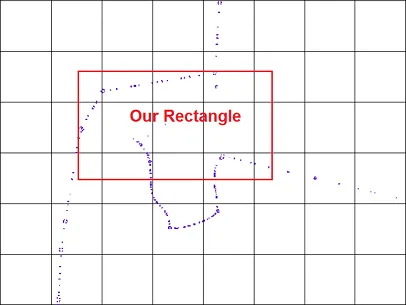
想象一种情况,你需要在给定的矩形中查找点。这个查询分为两步:
第一次过滤创建了一个候选集,并防止对研究区域中的所有点逐一进行测试。
第二次过滤是准确检查,使用矩形坐标来测试候选点。
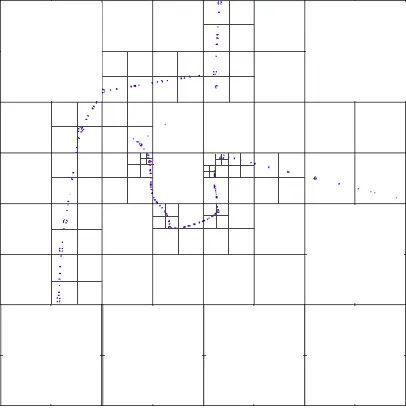
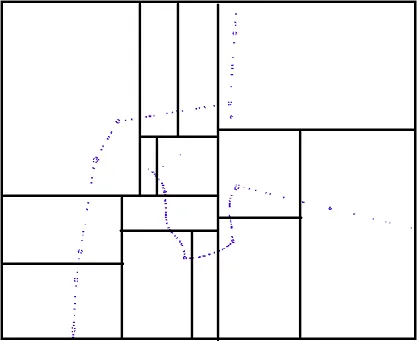
这是一个关于四叉树的示例代码,旨在创建5000个随机点。
#include<stdio.h>
#include<stdlib.h>
//Removed windows-specific header and functions
//-------------------------------------
// STRUCTURES
//-------------------------------------
struct Point
{
int x;
int y;
};
struct Node
{
int posX;
int posY;
int width;
int height;
Node *child[4]; //Changed to Node *child[4] rather than Node ** child[4]
Point pointArray[5000];
};
//-------------------------------------
// DEFINITIONS
//-------------------------------------
void BuildQuadTree(Node *n);
void PrintQuadTree(Node *n, int depth = 0);
void DeleteQuadTree(Node *n);
Node *BuildNode(Node *n, Node *nParent, int index);
//-------------------------------------
// FUNCTIONS
//-------------------------------------
void setnode(Node *xy,int x, int y, int w, int h)
{
int i;
xy->posX = x;
xy->posY = y;
xy->width= w;
xy->height= h;
for(i=0;i<5000;i++)
{
xy->pointArray[i].x=560;
xy->pointArray[i].y=560;
}
//Initialises child-nodes to NULL - better safe than sorry
for (int i = 0; i < 4; i++)
xy->child[i] = NULL;
}
int randn()
{
int a;
a=rand()%501;
return a;
}
int pointArray_size(Node *n)
{
int m = 0,i;
for (i = 0;i<=5000; i++)
if(n->pointArray[i].x <= 500 && n->pointArray[i].y <= 500)
m++;
return (m + 1);
}
//-------------------------------------
// MAIN
//-------------------------------------
int main()
{
// Initialize the root node
Node * rootNode = new Node; //Initialised node
int i, x[5000],y[5000];
FILE *fp;
setnode(rootNode,0, 0, 500, 500);
// WRITE THE RANDOM POINT FILE
fp = fopen("POINT.C","w");
if ( fp == NULL )
{
puts ( "Cannot open file" );
exit(1);
}
for(i=0;i<5000;i++)
{
x[i]=randn();
y[i]=randn();
fprintf(fp,"%d,%d\n",x[i],y[i]);
}
fclose(fp);
// READ THE RANDOM POINT FILE AND ASSIGN TO ROOT Node
fp=fopen("POINT.C","r");
for(i=0;i<5000;i++)
{
if(fscanf(fp,"%d,%d",&x[i],&y[i]) != EOF)
{
rootNode->pointArray[i].x=x[i];
rootNode->pointArray[i].y=y[i];
}
}
fclose(fp);
// Create the quadTree
BuildQuadTree(rootNode);
PrintQuadTree(rootNode); //Added function to print for easier debugging
DeleteQuadTree(rootNode);
return 0;
}
//-------------------------------------
// BUILD QUAD TREE
//-------------------------------------
void BuildQuadTree(Node *n)
{
Node * nodeIn = new Node; //Initialised node
int points = pointArray_size(n);
if(points > 100)
{
for(int k =0; k < 4; k++)
{
n->child[k] = new Node; //Initialised node
nodeIn = BuildNode(n->child[k], n, k);
BuildQuadTree(nodeIn);
}
}
}
//-------------------------------------
// PRINT QUAD TREE
//-------------------------------------
void PrintQuadTree(Node *n, int depth)
{
for (int i = 0; i < depth; i++)
printf("\t");
if (n->child[0] == NULL)
{
int points = pointArray_size(n);
printf("Points: %d\n", points);
return;
}
else if (n->child[0] != NULL)
{
printf("Children:\n");
for (int i = 0; i < 4; i++)
PrintQuadTree(n->child[i], depth + 1);
return;
}
}
//-------------------------------------
// DELETE QUAD TREE
//-------------------------------------
void DeleteQuadTree(Node *n)
{
if (n->child[0] == NULL)
{
delete n;
return;
}
else if (n->child[0] != NULL)
{
for (int i = 0; i < 4; i++)
DeleteQuadTree(n->child[i]);
return;
}
}
//-------------------------------------
// BUILD NODE
//-------------------------------------
Node *BuildNode(Node *n, Node *nParent, int index)
{
int numParentPoints, i,j = 0;
// 1) Creates the bounding box for the node
// 2) Determines which points lie within the box
/*
Position of the child node, based on index (0-3), is determined in this order:
| 1 | 0 |
| 2 | 3 |
*/
setnode(n, 0, 0, 0, 0);
switch(index)
{
case 0: // NE
n->posX = nParent->posX+nParent->width/2;
n->posY = nParent->posY+nParent->height/2;
break;
case 1: // NW
n->posX = nParent->posX;
n->posY = nParent->posY+nParent->height/2;
break;
case 2: // SW
n->posX = nParent->posX;
n->posY = nParent->posY;
break;
case 3: // SE
n->posX = nParent->posX+nParent->width/2;
n->posY = nParent->posY;
break;
}
// Width and height of the child node is simply 1/2 of the parent node's width and height
n->width = nParent->width/2;
n->height = nParent->height/2;
// The points within the child node are also based on the index, similiarily to the position
numParentPoints = pointArray_size(nParent);
switch(index)
{
case 0: // NE
for(i = 0; i < numParentPoints-1; i++)
{
// Check all parent points and determine if it is in the top right quadrant
if(nParent->pointArray[i].x<=500 && nParent->pointArray[i].x > nParent->posX+nParent->width/2 && nParent->pointArray[i].y > nParent->posY + nParent->height/2 && nParent->pointArray[i].x <= nParent->posX + nParent->width && nParent->pointArray[i].y <= nParent->posY + nParent-> height)
{
// Add the point to the child node's point array
n->pointArray[j].x = nParent ->pointArray[i].x;
n->pointArray[j].y = nParent ->pointArray[i].y;
j++;
}
}
break;
case 1: // NW
for(i = 0; i < numParentPoints-1; i++)
{
// Check all parent points and determine if it is in the top left quadrant
if(nParent->pointArray[i].x<=500 && nParent->pointArray[i].x > nParent->posX && nParent->pointArray[i].y > nParent->posY+ nParent-> height/2 && nParent->pointArray[i].x <= nParent->posX + nParent->width/2 && nParent->pointArray[i].y <= nParent->posY + nParent->height)
{
// Add the point to the child node's point array
n->pointArray[j].x = nParent ->pointArray[i].x;
n->pointArray[j].y = nParent ->pointArray[i].y;
j++;
}
}
break;
case 2: // SW
for(i = 0; i < numParentPoints-1; i++)
{
// Check all parent points and determine if it is in the bottom left quadrant
if(nParent->pointArray[i].x<=500 && nParent->pointArray[i].x > nParent->posX && nParent->pointArray[i].y > nParent->posY && nParent->pointArray[i].x <= nParent->posX + nParent->width/2 && nParent->pointArray[i].y <= nParent->posY + nParent->height/2)
{
// Add the point to the child node's point array
n->pointArray[j].x = nParent ->pointArray[i].x;
n->pointArray[j].y = nParent ->pointArray[i].y;
j++;
}
}
break;
case 3: // SE
for(i = 0; i < numParentPoints-1; i++)
{
// Check all parent points and determine if it is in the bottom right quadrant
if(nParent->pointArray[i].x<=500 && nParent->pointArray[i].x > nParent->posX + nParent->width/2 && nParent->pointArray[i].y > nParent->posY && nParent->pointArray[i].x <= nParent->posX + nParent->width && nParent->pointArray[i].y <= nParent->posY + nParent->height/2)
{
// Add the point to the child node's point array
n->pointArray[j].x = nParent ->pointArray[i].x;
n->pointArray[j].y = nParent ->pointArray[i].y;
j++;
}
}
break;
}
return n;
}
我认为在这种情况下,kd树比四叉树更好,因为使用四叉树时,在查找最近邻居时,最接近的对象可能会被放置在节点之间的另一侧。相反,kd树允许实现非常高效的最近邻搜索,尽管插入和删除会更加困难,但可以保持树的平衡。
有几个逻辑错误:
for(i = 0; i <= numParentPoints-1; i++)
return m;