以上的解决方案对我没有用,因为我的数据有多个交叉点,以下是帮助我的方法。
这个解决方案引入了一个函数,稍微插值了数据集,即使用fill_data_gaps()函数来插值交叉点:
library(tidyverse)
find_intercept <- function(x1, x2, y1, y2, l1, l2) {
d <- (x1 - x2) * ((l1 - l2) - (y1 - y2))
a <- (x1*y2 - x2*y1)
b <- (x1*l2 - x2*l1)
px <- (a*(x1 - x2) - (x1 - x2)*b) / d
py <- (a*(l1 - l2) - (y1 - y2)*b) / d
list(x = px, y = py)
}
fill_data_gaps <- function(data, xvar, yvar, levelvar) {
xv <- deparse(substitute(xvar))
yv <- deparse(substitute(yvar))
lv <- deparse(substitute(levelvar))
data <- data %>% arrange({{xvar}})
grp <- ifelse(data[[yv]] >= data[[lv]], "up", "down")
sp <- split(data, cumsum(grp != lag(grp, default = "")))
its <- lapply(seq_len(length(sp) - 1), function(i) {
lst <- sp[[i]] %>% slice(n())
nxt <- sp[[i + 1]] %>% slice(1)
it <- find_intercept(x1 = lst[[xv]], x2 = nxt[[xv]],
y1 = lst[[yv]], y2 = nxt[[yv]],
l1 = lst[[lv]], l2 = nxt[[lv]])
it[[lv]] <- it[["y"]]
setNames(as_tibble(it), c(xv, yv, lv))
})
for (i in seq_len(length(sp))) {
dir <- ifelse(mean(sp[[i]][[yv]]) > mean(sp[[i]][[lv]]), "up", "down")
if (i > 1) sp[[i]] <- bind_rows(its[[i - 1]], sp[[i]])
if (i < length(sp)) sp[[i]] <- bind_rows(sp[[i]], its[[i]])
sp[[i]] <- sp[[i]] %>% mutate(.dir = dir)
}
bind_rows(sp)
}
创建一些虚假数据。
N <- 10
set.seed(1235)
data <- tibble(
year = 2000:(2000 + N),
value = c(100, 100 + cumsum(rnorm(N))),
level = c(100, 100 + cumsum(rnorm(N)))
)
data
data2 <- fill_data_gaps(data, year, value, level)
data2
请注意,我们有更多带插值值的行(例如第3、4、7、8行)。
然后,我们可以像往常/预期一样使用
ggplot2::geom_ribbon()。
ggplot(data2, aes(x = year)) +
geom_ribbon(aes(ymin = level, ymax = value, fill = .dir)) +
geom_line(aes(y = value)) +
geom_line(aes(y = level), linetype = "dashed") +
scale_fill_manual(name = "Dir", values = c("up" = "green", "down" = "red"))
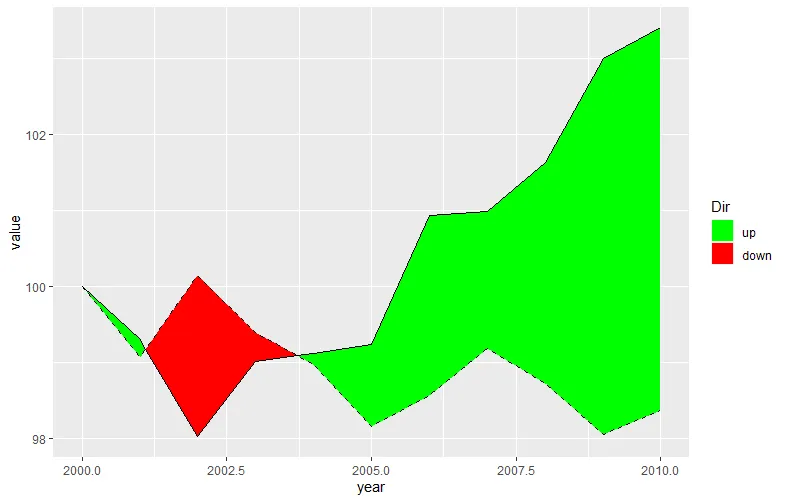
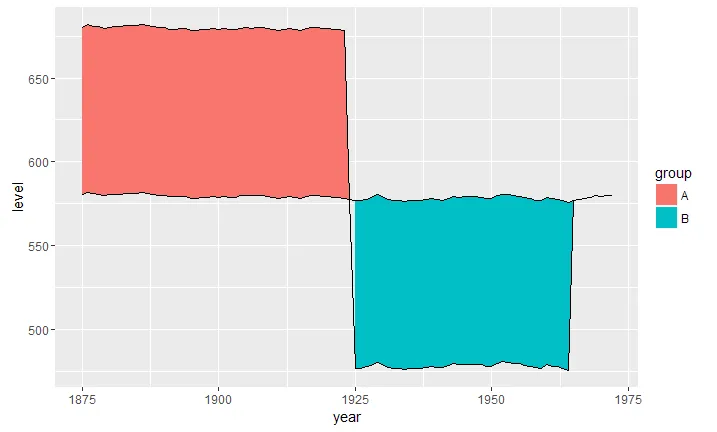
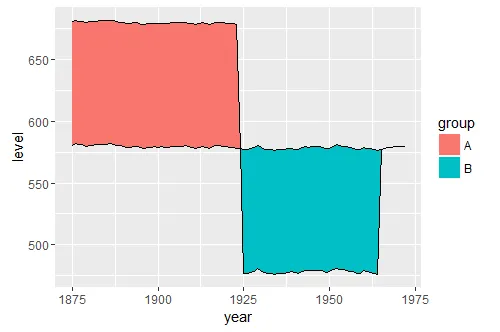
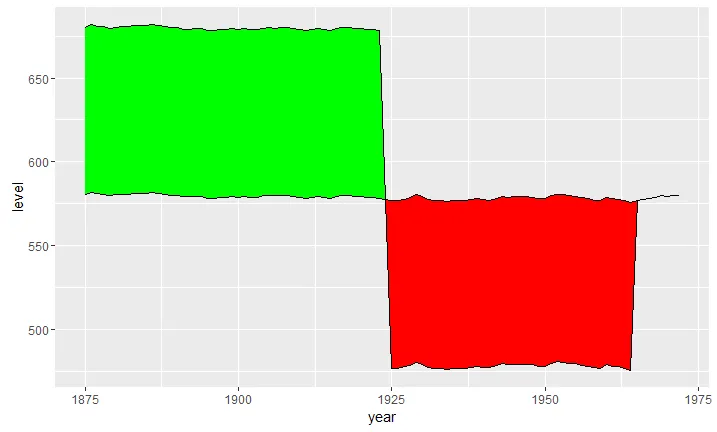
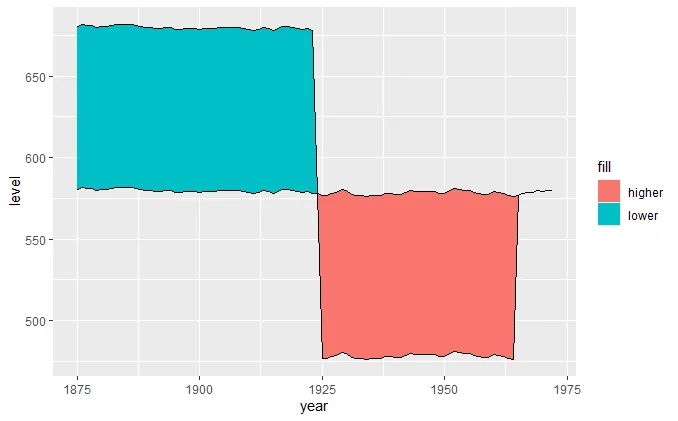
ggplot2需要列数据,所以你需要有一列可以作为ymin和ymax值的数据。不过使用tidyr::spread()将长格式的数据转换成所需格式是相当直观的。 - Jonathan Carroll