大家早上好。我试图找出两行之间的差异。我在尝试编写一个公式,但感觉可能有更简单的答案,而且我的代码不完美。以下是我的示例数据集。
cols = ['Name', 'Math', 'Science', 'English', "History"]
data = [['Tom', 100, 93, 95, 92], ['Nick', 89, 75, 82, 57], ['Julie', 99, 89, 76, 88], ['Sarah', 79, 78, 94, 88]]
df = pd.DataFrame(data, columns=cols)
df
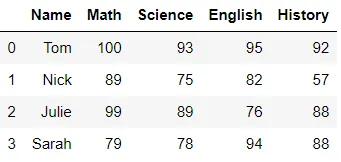
输出结果如下:
我目前的(不起作用的)公式是:
students = ['Tom', 'Nick', 'Julie', 'Sarah']
differences = []
def student_diff(student):
for col in df.columns[1:]:
for classmate in students:
differences.append(abs(student[col] - classmate[col]))
print (student, differences.mean())
student_diff('Tom')
错误如下:
TypeError: string indices must be integers
总的来说,我希望输出结果是这样的(例如Tom):
Nick 19.25
data.iloc[0]和data.iloc[0, :]之间是否有任何行为差异?我没有看到任何区别,但我对NumPy和Pandas相对较新。干杯! - Philip Wragedata.iloc[1:]和data.iloc[1:, :]也是一样的。我有时会包括第二个:,如果我知道以后需要返回并切片列。所以,如果你对除了数学以外的所有内容都感到好奇,你可以添加return abs(data.iloc[0, 1:] - data.iloc[1:, 1:]).mean(axis=1)。 - It_is_Chris:片段指定为第二个索引,您正在表示您想要每一列 - 这将是默认行为 - 但是您留下了一个占位符以便在未来的计算中进行调整。感谢澄清! - Philip Wrage